Announcing new framework for building, deploying and automating machine learning pipelines: human validation
End-to-end machine learning and pipeline automation is a popular topic these days in the data science and engineering community. Companies are deploying more models to production, and they are re-fitting, re-training and re-calibrating their models continuously to keep their models running at peak performance.
It is remarkable to see a fully automated end-to-end pipeline in action. Watching it fetch the latest data, run through preprocessing and feature engineering, select the best model and finally update a production endpoint — all also can be triggered automatically due to model decay while in production. Advanced ML automation at scale is a major evolutionary step that will radically change the AI industry.
One of the problems with automating models deployment and retraining is that we think of models as software, which is not. Machine learning adds uncertainty to your software stack. It doesn’t matter how accurate your model is, or how confident you are in it — a slight change in data can introduce bias or impact model decisions, ultimately affecting your users, their experience and business outcome. It’s important for corporations to maintain the highest level of governance for their AI applications and perform responsible AI and ML automation to keep the models in check. That is why cnvrg.io is releasing new features to ensure end-to-end governance throughout the ML lifecycle.
Responsible AI and ML automation with Human Validations
We have developed a new framework for building, deploying and automating machine learning pipelines: human validation. A framework that enables high level automation (or complete automation) with the option to involve a human to approve production deployment – maintaining a fast and responsible ML deployment.
Just like merging a PR in git might trigger a CD pipeline, the above framework will allow you to view a model and its report (data, algorithms, hyperparameter and metrics) before deploying it to the production environment. cnvrg.io comes packaged with 100% reproducible data science, ML pipeline automation and model deployment enabling a complete CICD ML pipeline with human validation.
How does it work?
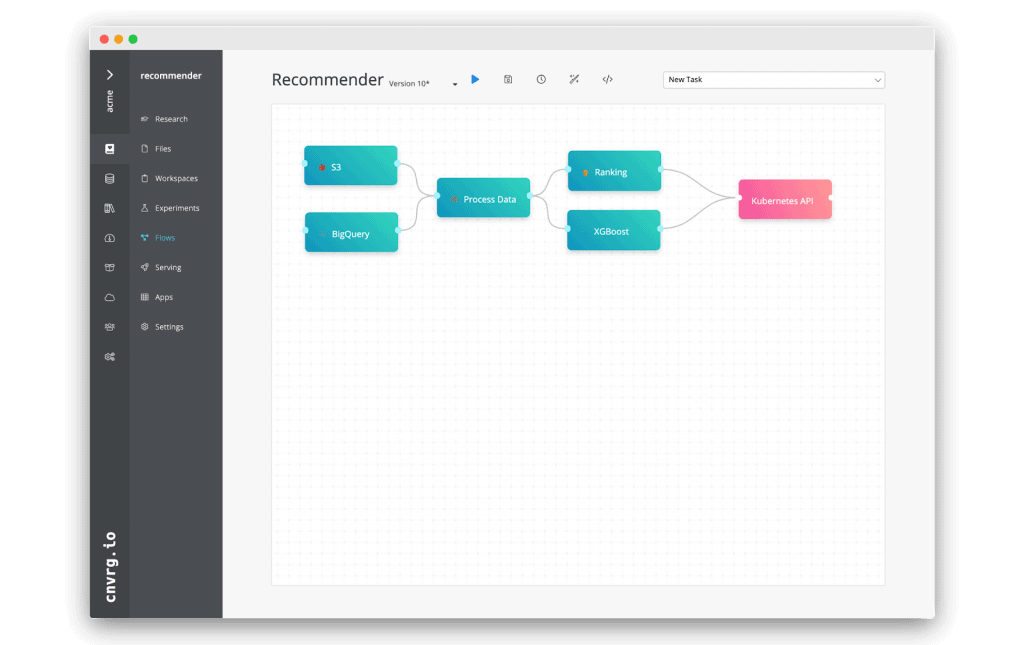
Here’s a real life example of how this feature can be used with cnvrg.io. Assume we have the following pipeline set: A recommendation engine built by ingesting data from S3 and BigQuery, running preprocessing using Spark on Kubernetes, followed by model training using TensorFlow and XGBoost over GPU and CPU clusters. Finally, cnvrg.io will pick the top performing model and a Kubernetes endpoint is rolled over to the champion model. This pipeline runs on a programmable recurring basis – in this case once a week. It is 100% automated wherein each week it fetches the latest data, re-trains and re-deploys the model.
We will add a mechanism ensuring that every time a new model is ready for deployment, it needs to be explicitly approved by the relevant data scientist or product manager. In this example, we are deploying a recommendation engine. Our recommendation engine is used by millions of users, and we want to be confident that any production update is being carefully critiqued before release.
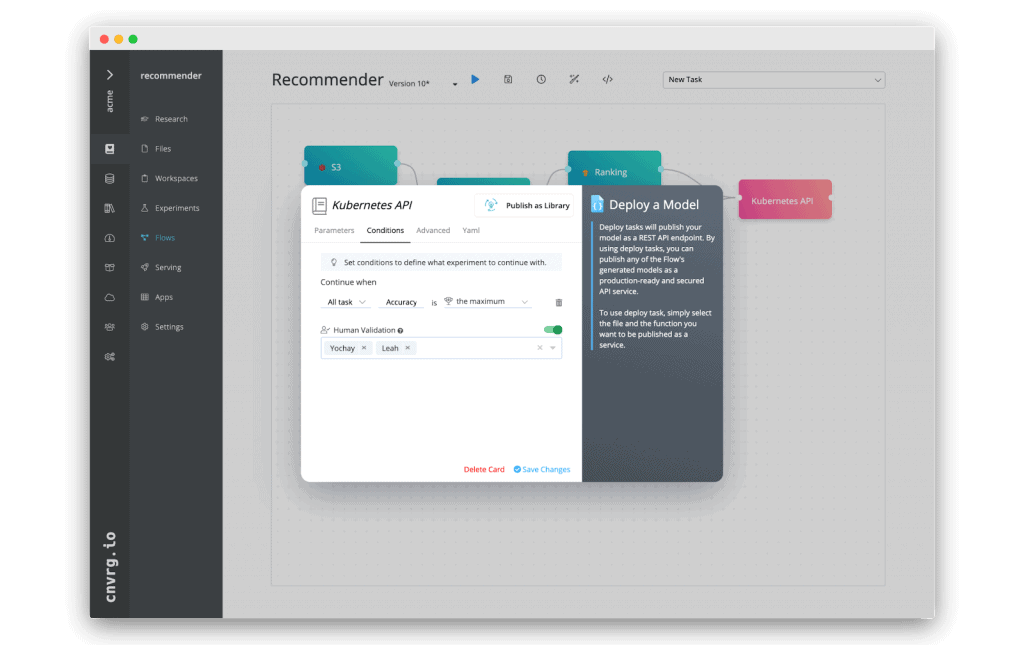
With cnvrg.io’s human validation – we can update the “deployment” task and add a condition that it will initiate deployment, only after a human reviews it and grants approval:
This flow can also be modified using a YAML config file by adding the following condition to a task: objective: human_validation
target: username,username2
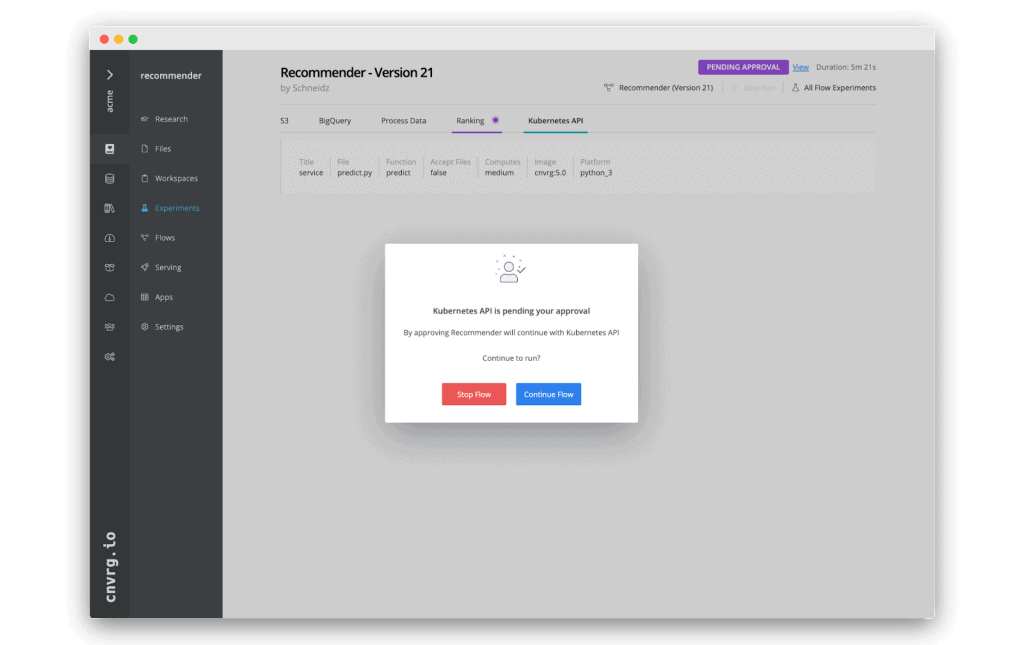
Then, each time the pipeline runs and reaches the deployment component, it will email the designated decision makers “username, username2” alerting them that the task is waiting for their approval. They can then inspect the model and either approve the deployment or prohibit the flow from advancing.
Looking to build your own ML pipelines? Start for free with cnvrg.io CORE – a community ML and MLOps platform running on Kubernetes: