


Have you ever worked with an LLM, and wished for a way to add new or updated information to the model’s knowledge without having to retrain? Well, this blog is for you! This is the first in a two-part series on building an AI app with LangChain using cnvrg.io’s MLOps platform to manage the development workflow. I’ll show you how to enhance Large Language Models (LLMs) like ChatGPT with cutting-edge tools like LangChain and vector databases. These tools help overcome the knowledge limitations of LLMs, making AI even smarter and more reliable.
In this blog, I’ll go over the limitations of LLMs when it comes to managing knowledge and context. Then, in part two, I’ll walk you through the process of building a RAG-enhanced LLM chatbot.
Let’s see how to build and empower your AI applications with new levels of intelligence and efficiency!
The Challenge of Augmenting Language Models with Additional Knowledge
At the heart of enhancing LLMs like ChatGPT lies a significant challenge:
How do we equip these models with up-to-date knowledge beyond their training data, or infuse them with specific data for more tailored results, while also addressing their context limitations?
Language models, by design, are trained on vast datasets available up until a certain point in time. Post-training, they don’t automatically update with new information. This poses a problem in a world where knowledge is constantly evolving. As a result, these models might lack the latest data or specific insights that users need.
Moreover, LLMs are constrained by the amount of context they can consider in a single interaction. This limitation means they can’t always leverage large amounts of relevant data in one go, which can affect the depth and relevance of their responses.
Just increasing the size of these models or stuffing more information into the prompt isn’t a viable solution. Larger models can be more powerful, but they don’t inherently solve the problem of staying current or handling vast, specific datasets effectively. Similarly, overloading the prompt with information can lead to a decrease in the quality of the model’s responses, as it struggles to balance all the provided data.
The Role of LangChain and vector database in Enhancing LLMs
To address these challenges, innovative tools like LangChain and vector databases are being increasingly adopted. LangChain, for instance, helps by orchestrating different AI components to work together. With LangChain, developers can connect a series of pre-built prompts to retrieve information from external databases, search engines, or specialized algorithms. This amalgamation allows the model to pull in the latest information or specific data relevant to the user’s query, thereby extending its knowledge base and applicability.
Vector databases, on the other hand, aid in managing and retrieving large datasets efficiently. Because they represent the semantics of text numerically as vectors, vector databases can use mathematical operations to enable speedy data retrieval based on semantic similarity, which can then be integrated into the model’s responses. This enhances the model’s ability to handle specific, detailed queries that require deep dives into large datasets.
Creative use of these tools makes LLMs more useful, accurate, and reliable in a variety of scenarios. This blog will explore these techniques in depth, demonstrating how they can transform the way we interact with and leverage the power of LLMs.
How LLM are changing software development
LLMs provide advantages developers to build applications rapidly :
Easier natural language applications: Developers can build diverse applications, from AI-driven chatbots and virtual assistants to advanced content creation tools, language translators, and personalized recommendation systems. For example, developers are creating advanced, super-personalized agents that can chat more naturally, provide more relevant assistance, understand languages better, and give spot-on recommendations, making them much more capable and tailored to you than Siri or Alexa.
Faster delivery: Instead of building AI models from scratch, developers can use existing LLMs and customize them for their needs. This speeds up the development process and makes it more efficient.
Customized solutions with less glue code: With LLMs, especially through frameworks like LangChain, developers can create applications that are tailored to specific industries or user needs without having to write custom code from scratch.. For example, a legal document analysis tool, a health advice chatbot, or a content creation tool for marketers.
Simplifying LLM Apps and Their Impact on Modern App Development
Think of traditional software applications as a recipe book. They follow set instructions (code) to perform tasks, like how a recipe guides you to make a dish. They’re structured, layer by layer, like chapters in the book, each handling a different part of the process.
Now, enter LLM apps – these are more like having a conversation with a skilled chef. Instead of just following pre-written recipes, they can understand and respond to your cooking questions, offering tailored advice based on past conversations. This is thanks to their ‘memory system’ – a bit like the chef remembering your past chats about food.Once you end the session, it’s like the chef forgets who you are and what you talked about. So, each time you start a new session, it’s as if you’re meeting the chef for the first time, with no memory of past interactions.
The secret ingredient for LLM apps is the vector database. It’s like a magical cookbook that not only has recipes but understands the essence of each dish. It uses ‘vectorized embeddings’, like turning words into numbers so computers can understand how similar they are to each other. It’s like giving each word a unique code that shows what it means and how it relates to other words. So, when you ask for a dish that’s sweet and spicy, the vector database helps the LLM app understand exactly what you mean, beyond just the words.
With LLM apps, app development shifts from just following instructions to having a dynamic, understanding partner. This means apps can offer more personalized, context-aware responses and solutions – like having a chef who knows your taste and can recommend dishes accordingly.
Increasing Adoption of Retrieval Augmented Generation in 2024
Retrieval-augmented generation (RAG) is an artificial intelligence (AI) framework that retrieves data from external sources of knowledge to improve the quality of responses. This natural language processing technique is commonly used to make LLMs more accurate and up to date.
The development of retrieval augmented generation has marked a significant advancement in the field, with projects like Intel’s fastRAG leading the charge. fastRAG is a cutting-edge research framework focused on creating efficient, retrieval-augmented generative models and applications. It combines the latest LLMs and information retrieval technologies, providing a robust toolkit for researchers and developers aiming to push the boundaries of retrieval-augmented generation. This innovation represents a leap forward in making AI systems more accurate and insightful.
RAG systems take it further, combining conversation with research – providing answers that are not only smart but also informed by the latest, most relevant information.
Traditional Software Applications VS LLM apps:
et’s break down traditional software applications, LLM apps, and RAG systems in a simple way to understand how they work and their impact on modern app development.
Traditional Software Applications:
This diagram represents the typical architecture of a web application, broken down into four key components, each with a specific role in handling a user’s interaction with the system:

The client is where the user starts talking to the app, like when you walk into a store and look around.
The frontend is what you see on the screen, like the store’s layout and shelves. It shows you stuff and takes your questions to the backend. The backend is the behind-the-scenes area, like the store’s back office, where all the hard work happens to figure out what you need. Lastly, the database is like a storage room that holds all the information, pulling out what’s needed when the backend asks for it.
LLM Apps:
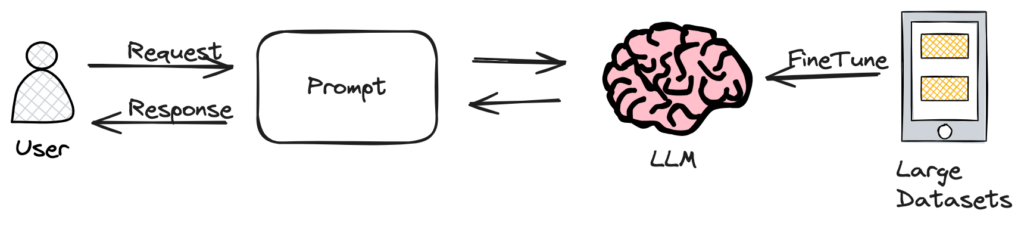
In the image above, we see a simplified flow of how apps using LLMs work.
The user, like someone sending a text message, starts by inputting a query or request into the client interface of the app. This is like asking a question. The app takes this question and turns it into a prompt, which is a clear and structured way to present the query to the LLM—much like figuring out the right way to ask a friend for advice.
The LLM, which is like a brain filled with lots of information, receives the prompt and thinks about it. It then generates a response, similar to a friend texting you back with an answer. This response is then interpreted by the app, so it makes sense to the user, just as you would understand and use the advice a friend gives you.
Optionally, if the LLM needs more information, it can integrate with external sources—like asking other friends or looking something up on the internet—to make sure it provides the most accurate and helpful response. This is like doing a quick web search to check facts before replying to a friend’s question.
RAG Systems:
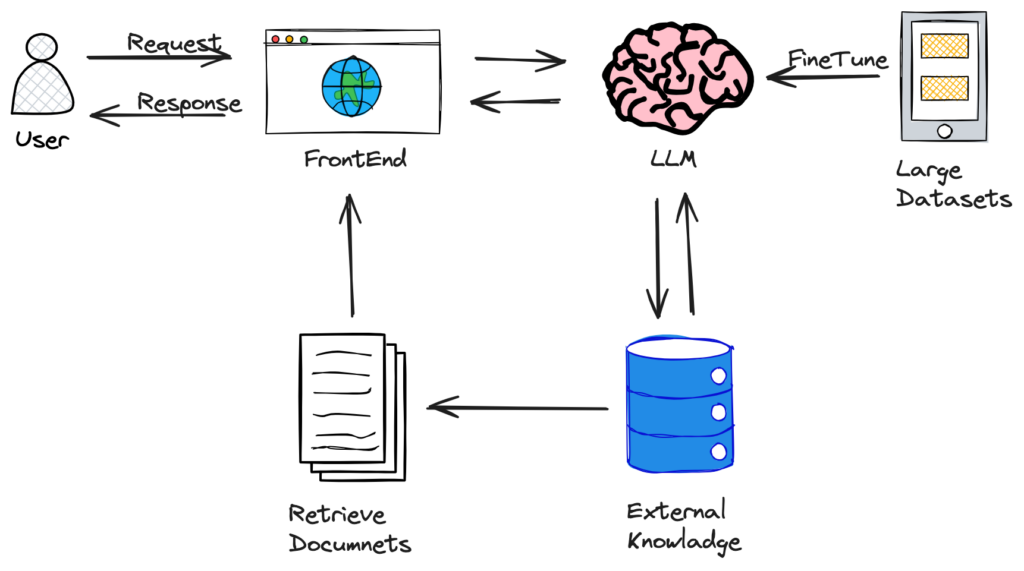
This diagram above illustrates the workings of RAG systems.
The process starts with the user, who inputs a question into the client interface—much like sending a text message. The system then formulates this question into a precise prompt, refining the query to get the best possible information.
Next, the RAG system acts like a friend who quickly looks up information before responding to your text. It retrieves relevant data from a large dataset or external knowledge sources, such as documents or the internet, to generate a well-informed response.
Once the response is generated, the system parses it, which means it organizes and interprets the information to ensure that it is clear and useful for the user.
Additionally, the RAG system can enhance its responses by actively pulling from external data sources, similar to how someone might reference books or search online for additional details to ensure the reply is as accurate and comprehensive as possible. This creates a more dynamic and enriched interaction between the user and the system.
Traditional apps are like well-organized stores – systematic and reliable but limited to what’s in stock. LLM apps turn the experience into a conversation – more flexible and personalized, but still based on what the AI knows.
In essence, as we move from traditional apps to LLM and now to RAG apps, it is like going from following a fixed set of instructions to having a smart conversation that adapts to your needs. Essentially LLMs informed by RAG make it easier to wrap a natural language interface around your application.
So that’s the background. Now let’s build something! In part two of this series, I’ll walk you through the process of integrating RAG with your LLM and building an AI-powered chatbot. See you there!







