How do you build a scalable machine learning infrastructure?
There are a few critical elements when building a machine learning infrastructure. You need your machine learning infrastructure to be built for scalability, and to provide you with visibility so you can build plans on top of your existing stack. We’ll first talk about the AI fabric comprising your compute resources, orchestration platforms like Kubernetes or OpenShift, and learn how to integrate that to your machine learning workflows. Components of a machine learning infrastructure also require solutions for data management, data version control and should provide a ML workbench for data scientists to give a simple way to train models, work on their research, and optimize models and algorithms. The last component of a scalable machine learning infrastructure is offering an easy and intuitive way to deploy models to production. One of the biggest challenges today, is that a lot of the models don’t make it to production because of hidden technical debt that the organization has. Your machine learning infrastructure should be agnostic, and easily integrate into your existing and future stack. It should be portable and utilize containers for simple deployments, and allow your data scientists to run experiments and workloads in one click. In the following sections we will dive into the main aspects of building a scalable machine learning infrastructure.
What are the biggest machine learning infrastructure challenges?
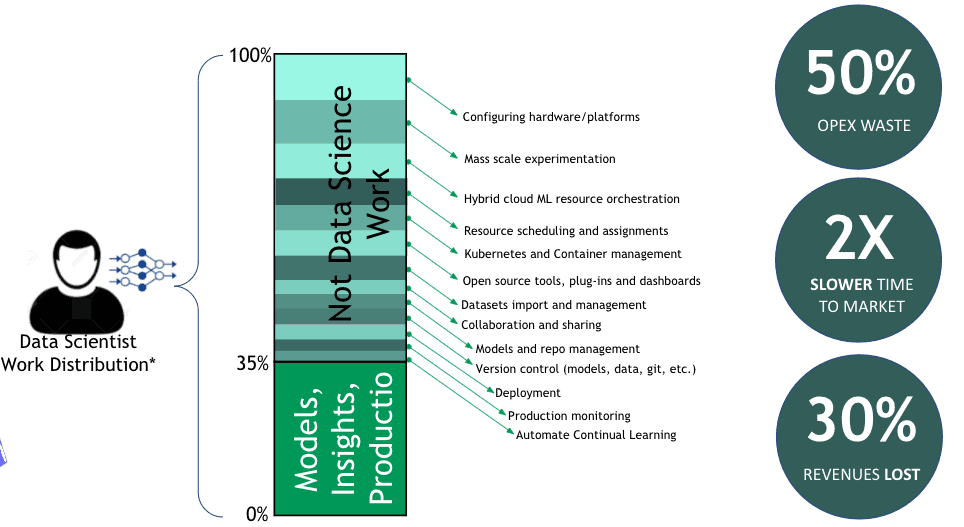
What are the biggest machine learning infrastructure business challenges?
How do you use MLOps best practices in your machine learning infrastructure?
What architecture can support machine learning at scale?
Now we will go over the steps to building an architecture that can support enterprise machine learning workloads at scale.
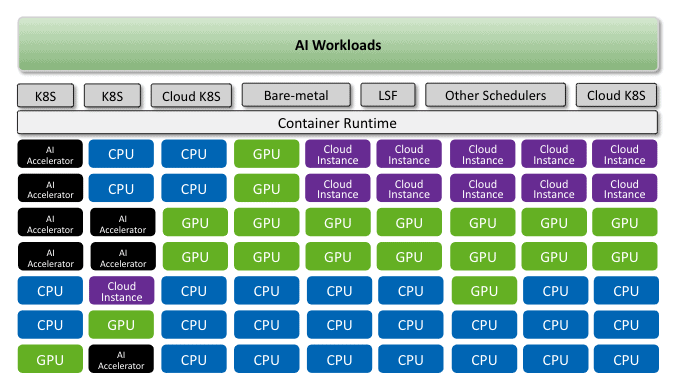
1. Containers
Containers are key to providing a flexible and portable machine learning infrastructure. With containers you can assign machine learning workloads to different compute resources. So GPUs, cloud GPUs, accelerators, any resource that you have can be assigned to each workload. Using containers can help distribute jobs on any of the resources that you have available. It is great for DevOps engineers because it provides a more portable and flexible way to manage workloads.
Containers help you to define an environment and are also great for reproducibility and reproducible data science. You can launch the containers anywhere on any cloud native technology. So, on-premise, Kubernetes cluster, bare-metal, using Docker simply and also cloud resources that have extensive support for all the different containers. You can also operate orchestration platforms like OpenShift, that make it easier for you to run and execute containers in the cluster.
2. Orchestration
When it comes to orchestration, you need to build something that is compute resource agnostic. While Kubernetes is becoming the standard way of deploying machine learning and for orchestration, there are so many flavors of Kubernetes. There is Rancher, there is OpenShift, there is Vanilla Kubernetes. Even for small deployments, there is MicroK8, and MiniKube. So when you’re designing your own infrastructure, you need to decide what kind of orchestration platform you’re aiming to support now and in the future. So you need to be able to design the stack in a way that fits your existing infrastructure while considering future infrastructure needs.
Also, whatever infrastructure you’re designing, you need to be able to leverage all the compute resources that you already have in your enterprise. So, if you have a large Spark cluster, Hadoop environment or you have bare-metal servers that are not running on Kubernetes – like large CPU clusters – then you need to be able to support those as well. You need to build an infrastructure that can integrate to the Hadoop cluster, that can leverage Spark, that can leverage YARN, and can leverage all the technology that your organization has. Not only that, but additionally you should consider how to manage all your compute resources in one place for all your data scientists across the industry to access and use in one click.
3. Hybrid cloud multi cloud infrastructure
What are the benefits of a hybrid cloud infrastructure for machine learning? This is a big topic that could easily take on its own post. But specifically in machine learning, a hybrid cloud infrastructure is ideal because usually machine learning workloads are stateless. That means that you may run a machine learning training for a day, or for two weeks, and terminate the machine. As long as all the models and data are being stored, you can simply terminate the machine, and forget about it. Hybrid cloud deployment for machine learning is unlike software in this way. In software you need to persist and make sure the database is shared across the hybrid environment. For hybrid cloud machine learning, it’s beneficial to control your resources in order to utilize the existing compute you already have. For example, let’s say an organization has eight GPUs on-premise, and 10 data scientists. Your organization would want to be able to utilize all of the eight GPUs, and only burst to cloud when it reaches 100% utilization or allocation. Cloud bursting is an essential capability that allows organizations to increase parameterization, and also reduces cloud costs. Not only that, but cloud bursting allows data scientists to easily scale machine learning activities.
4. Agnostic & open infrastructure
Flexibility and being able to easily extend your base platform is critical, because machine learning is evolving extremely fast. So you need to design your machine learning infrastructure in a way that enables you to easily extend it. That means that if there is a new technology, a new operator, a new platform that you want to integrate, you can easily do that without reconfiguring your entire infrastructure. If there is one thing you take from this guide on machine learning infrastructure is to pick your technologies carefully, make sure it is agnostic, and built for scale. That way you can quickly adopt new technologies and operators as they evolve.
Second, if your infrastructure is agnostic, you also need to think about your interface with data scientists. If your interface is not intuitive, then you will miss the benefits of the new technology into your infrastructure. Remember, data scientists are not DevOps engineers or IT. Often they are PhD’s in math and don’t want to work with YAML files or namespaces or deployments etc. They want to do what they were hired to do which is to work on their models. So you need somehow be able to abstract the interface for data scientists, especially if you’re using Kubernetes while providing them the flexibility and control that they need. Meaning that if there are data scientists or DevOps on your team who want to get into the internals of Kubernetes, you need to be able to allow that as well. In the end, it is all about supporting your data science and engineering teams to make them better professionals.
How do you schedule jobs on each of the different interfaces?
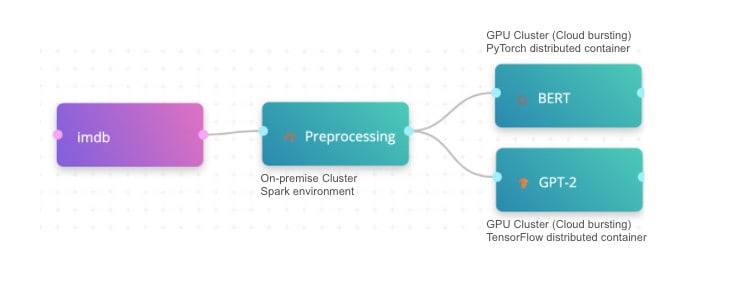
What are the examples of different hybrid environments?
Different enterprises require different types of environments for their machine learning. Many machine learning teams are running on legacy systems, or have their own resources available. Some enterprises require highly secure and governed infrastructures, and some are extremely diversified for different types of workloads. We have never encountered 2 infrastructures the same. The reality is that all infrastructures should be built around the need of the enterprise, not to conform to the platform. Here are some real life examples of diverse and supported scenarios from our customers.
1. Simplifying a complex and heterogeneous IT stack
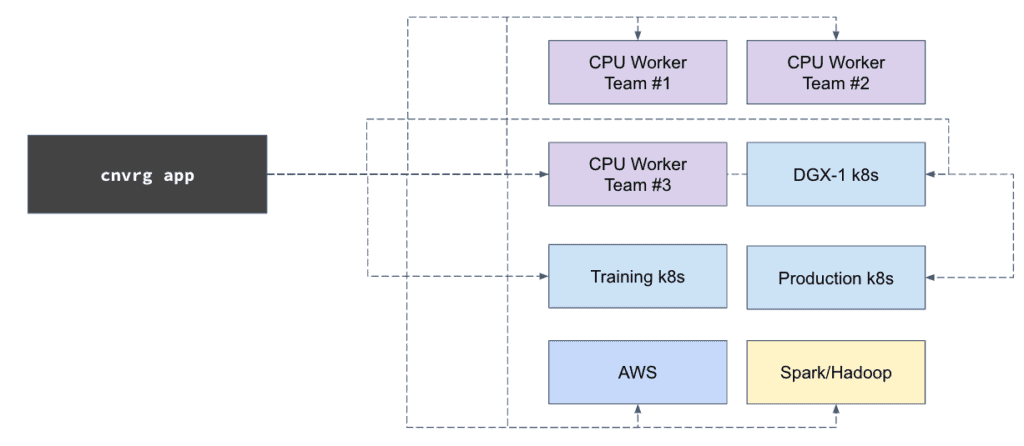
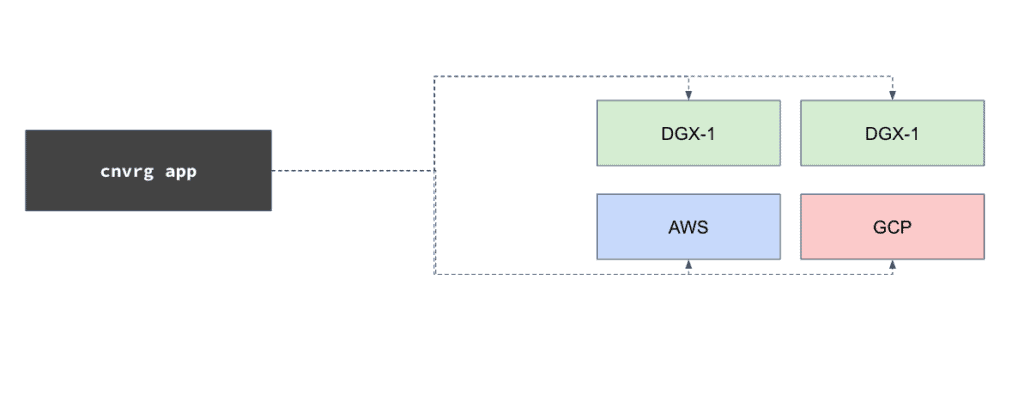
2. Increasing on-prem GPU utilization with hybrid and multi cloud setup
Another nice example is for a hybrid multi cloud environment. This customer has a DGX-1, and another DGX-1 both are on-premise. Those are used to serve two different teams today. It is organized so that they get a pool of 16 GPUs that can be consumed by anyone on the team. In addition, they have connected their cloud resources from AWS and GCP. This infrastructure allows them to increase on parameterization, and then burst to AWS and GCP, only once they’ve reached capacity. They can even prioritize the cloud bursting, so first burst on GCP and then burst on AWS or integrate spot or preemptive instances that will save you a lot of money.
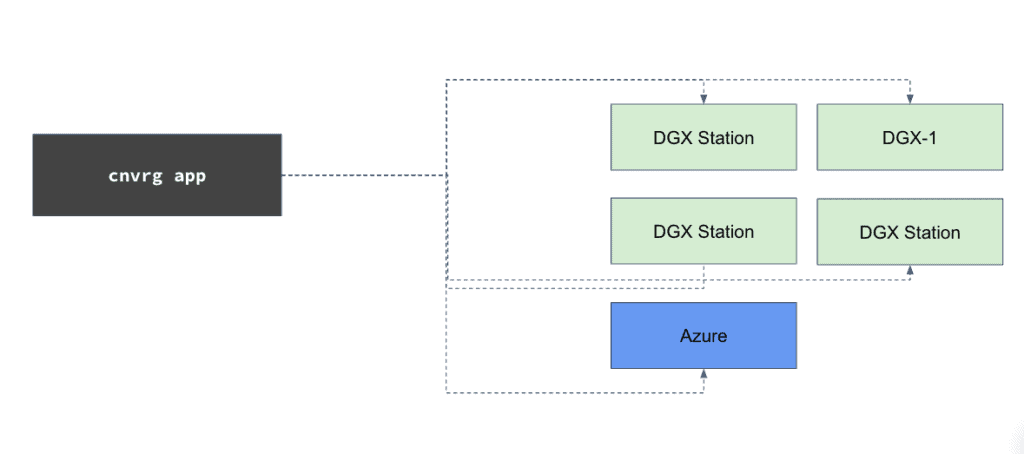
3. NVIDIA multiple DGXs with cloud bursting to Azure
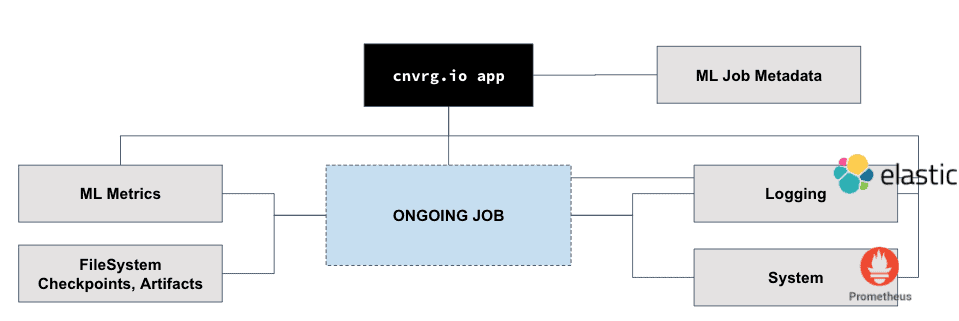
The ML infrastructure visibility checklist (10 Question you should ask as DS Manager)
When you have a diverse hybrid compute infrastructure for machine learning, one of the biggest challenges is managing the infrastructure. There are a few goals when managing your compute resources. One goal is to maximize utilization, and two is to maximize productivity of your data scientists. The number one infrastructure capability that can increase your utilization and productivity is with visibility. Visibility can help you make informed decisions about your infrastructure and machine learning workflow. Here are a few questions you should be asking yourself as a data science leader about building a visibility tool for your machine learning infrastructure.
1. What is the best way to track in real time so we know what is going on in the past, present and future?
2. What parameters do we need to track? Do you have data on the job, container, allocation and utilization?
3. Do you have a list of dependencies, or network configurations, or data, or storage configurations?
4. Are you able to see job logs such as what happened in the POD?
5. Do you have visibility into the container when the data scientist run this job?
6. Do you have system metrics? Can you see how much of the GPU is really utilized compared to what is really consumed by the user?
7. Do you have visibility into machine learning metrics and artifacts, so model weights, checkpoints etc?
8. Can your measure capacity? (ex. Do you know how many GPUs are connected to your cluster?)
9. Can you measure utilization? (ex. Do you know the total number GPUs available?)
10. Can you measure allocation? (ex. How many GPUs are being utilized at this time?)
These questions should help guide you towards a more transparent machine learning infrastructure. Once you have visibility into your server metrics, you will be able to start improving your performance.
How to build an MLOps visibility tool
What actions can I take to improve machine learning server utilization?
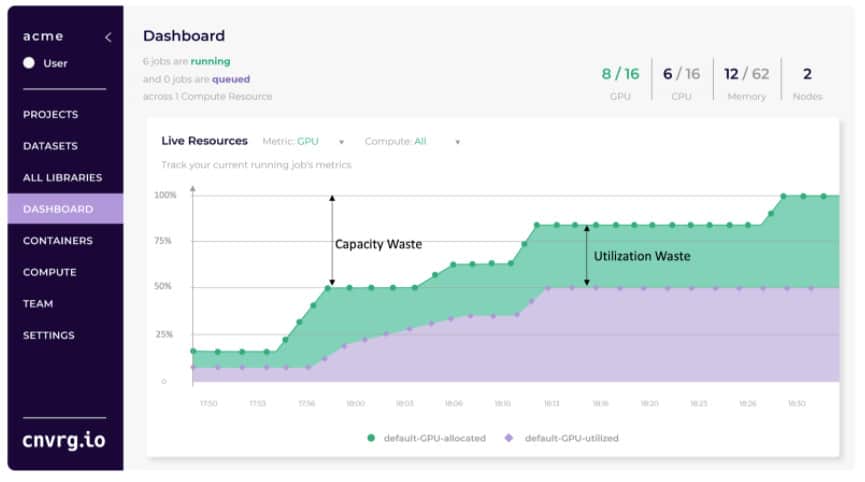
Once you are able to track the capacity waste with a visibility tool, you can use this knowledge to educate your data scientists on better ways to use resources. Here are a few actions you can take to maximize your machine learning server utilization:
1. Stop jobs that aren’t working
In the data science workflow wasteful situations can occur. Monitor for jobs that are stuck or aren’t using any of the resources allocated. For instance, perhaps a data scientist forgot to shut down a Jupyter Notebook. With live server visibility you can stop waste at the time it occurs.
2. Data-driven utilization insights
Operations teams can use raw data to analyze the overall machine learning workflow by user, job, container etc. Once the data is being collected, you can dive deeper into all the jobs that are running in the platform and extract insights. For example you can build a report on how many models are used in the cloud.
3. Define the key questions for your use case
Just like any data analysis, you need to define what kind of information is important for you, and stakeholders to understand. You can see if users are not utilizing all their hardware resources, or identify patterns of workloads that underperform, and adjust your strategy accordingly.
How to Plan Ahead? (how to use data driven ML infrastructure and capacity planning)
What is the future of machine learning infrastructure?
How can I integrate an MLOps infrastructure quickly?