

Over time, Kubernetes has become widely adopted in the data science community to run containerized deep learning workloads. GPUs, with their highly parallelized computations, are really what propelled deep learning out of the lab and into production use. But Kubernetes itself doesn’t offer native GPU sharing capabilities. Instead, it can only attach whole GPUs to containers, even if the containerized job only needs some of the GPU’s cores. So expensive processor cycles go to waste.
To improve GPU utilization, cnvrg.io has introduced MetaGPU, a new feature in Metacloud and self-managed cnvrg.io to share GPUs among multiple Kubernetes workloads. With vanilla Kubernetes, a resource like a GPU is presented as a whole unit. You specify the number of resources you need in terms of integers. With MetaGPU, we’ve made it possible to fractionalize GPUs into as many as 100 addressable units that can be dynamically allocated to different jobs as needed. Once MetaGPU is enabled in your environment, you can create custom compute templates in different sizings for your team’s self-service convenience.
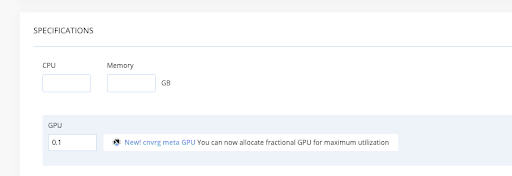
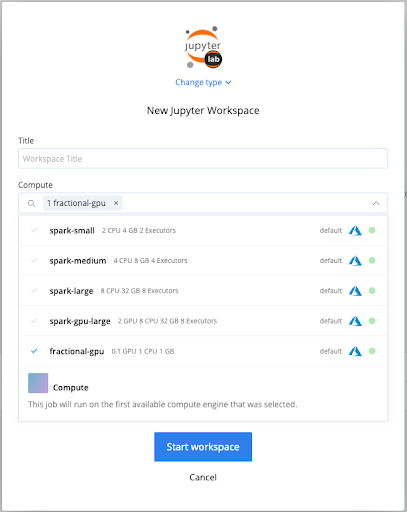
How does this work? Out of the box, Kubernetes supports basic compute resources.. Kubenetes extended resources give developers a way to provide additional resources, like GPUs. The MetaGPU plugin is a software component built with Kubernetes’ device plugin framework, the Nvidia Container Runtime, and the Nvidia Management Library. The plugin notifies each node’s Kubelet about the availability of GPUs.
With MetaGPU, a data scientist can experiment with GPU sizings and quickly converge on the minimum configuration for a given workload. MetaGPU’s fractional GPU sharing regime lets companies unleash the full capacity of their hardware so they can scale up their deep learning more quickly and efficiently.
Better yet, the source code is available under the MIT License. Get better utilization of your expensive GPUs! Learn more at cnvrg.io.com, and review the MetaGPU documentation.







