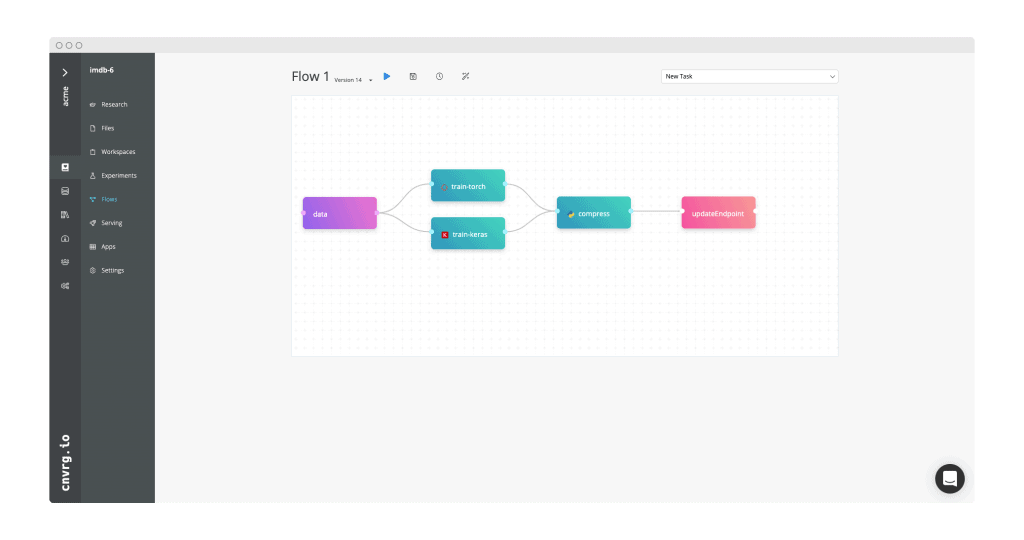
Train and deploy using NVIDIA deep-learning containers
Load data from S3 object storage, train with both TensorFlow and PyTorch deep-learning containers on NVIDIA GPUs, pick champion model and deploy to a production endpoint.
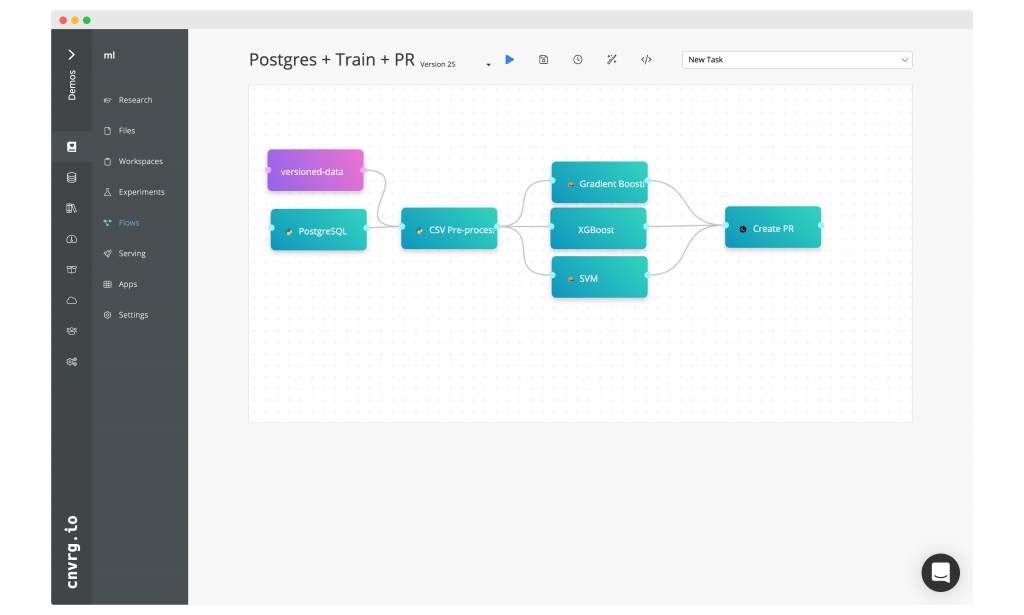
Train models on versioned data and create GitHub PR with champion model
Load and version data from PostgreSQL. Run through a preprocessing pipeline using Apache Spark on Kubernetes, train with multiple models with hyperparameter optimization for each. Compare metrics, pick top performing model and open a GitHub Pull-Request.
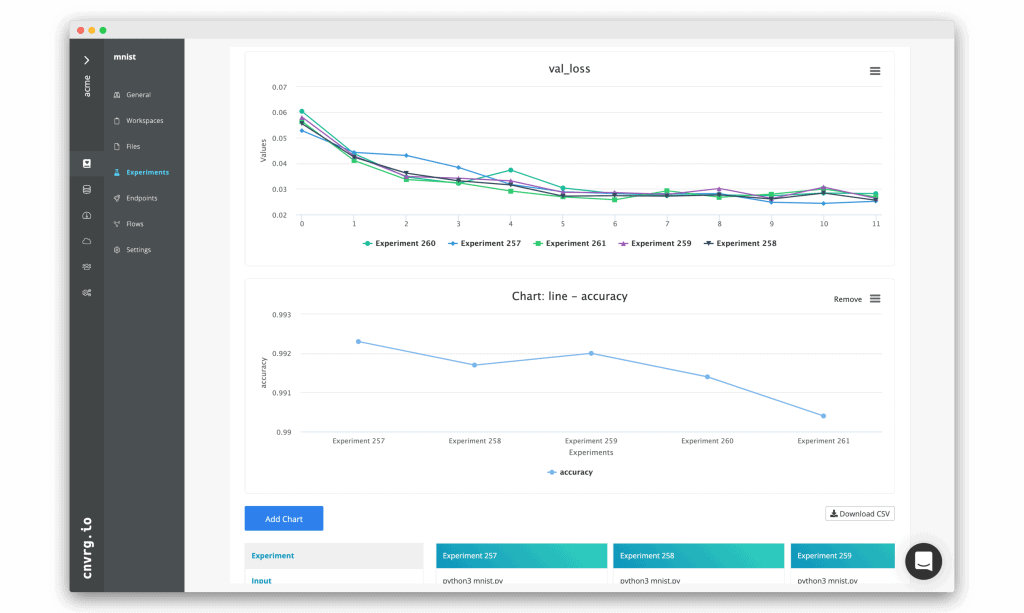
Train hundreds of models and show model comparison dashboard
Train and track hundreds of ML models. Use cnvrg.io to automatically track all models in real-time. Useful for research and iterative development workflows, and also for production model comparison.
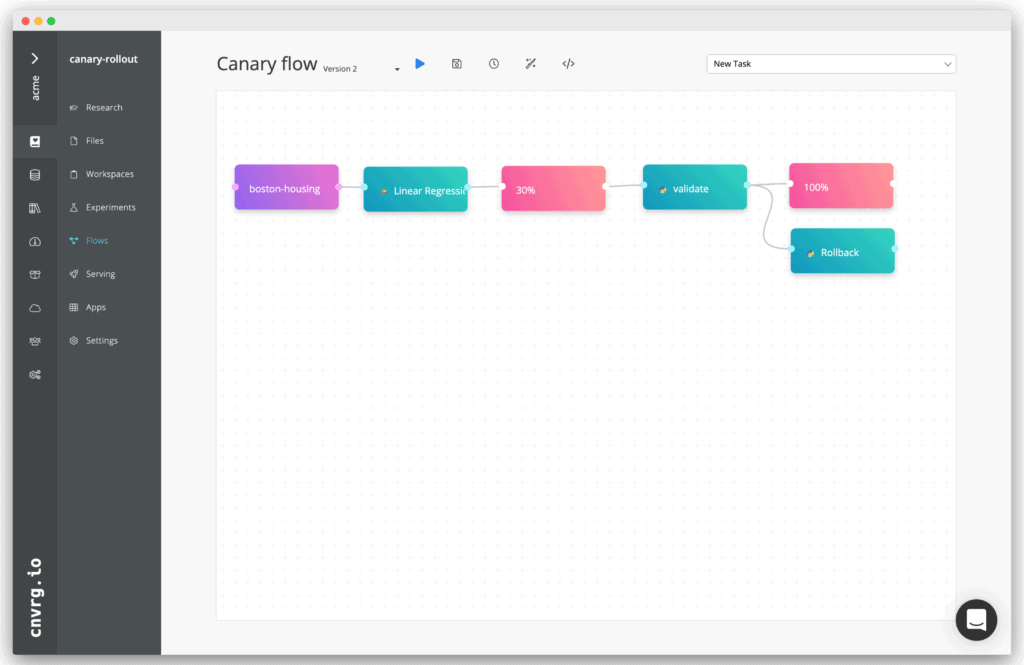
Deploy trained models with Canary Rollout and A/B testing
Automatic ML pipeline that trains models continuously based on new data snapshots, uses Canary Rollout to build a Champion/Challenger mechanism with auto traffic routing, validation and advanced conditions and rollback option for safe deployment
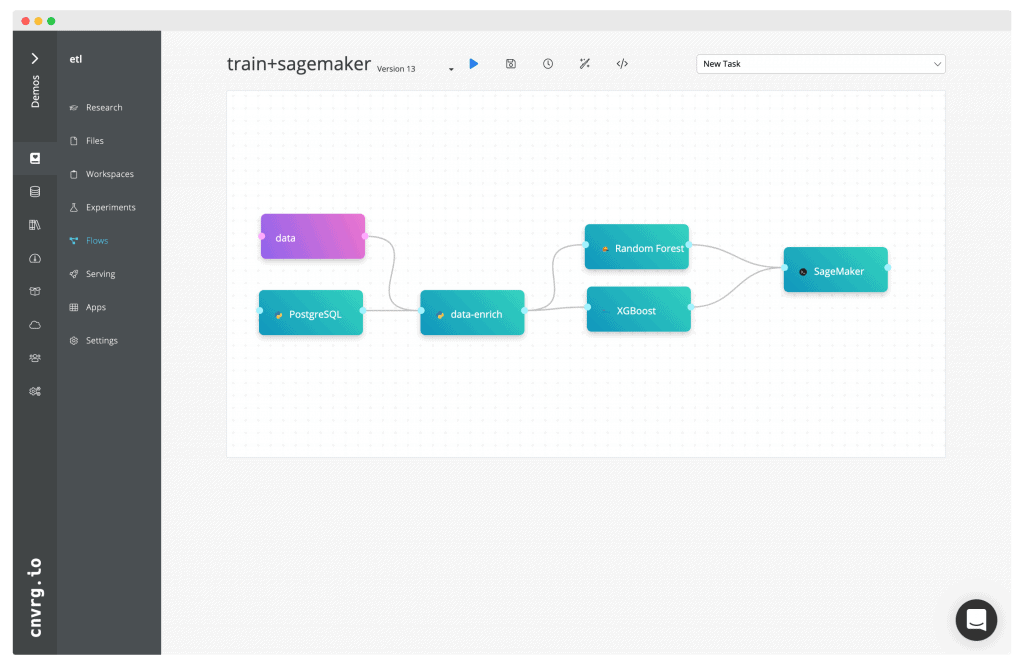
Train multiple models and select the best one to deploy to SageMaker
Build a pipeline that reads data from PostgreSQL, enrich it with external data sources (weather, holidays) and train two models with hyperparameter optimization - select the top model based on custom metrics and deploy it as to production using SageMaker
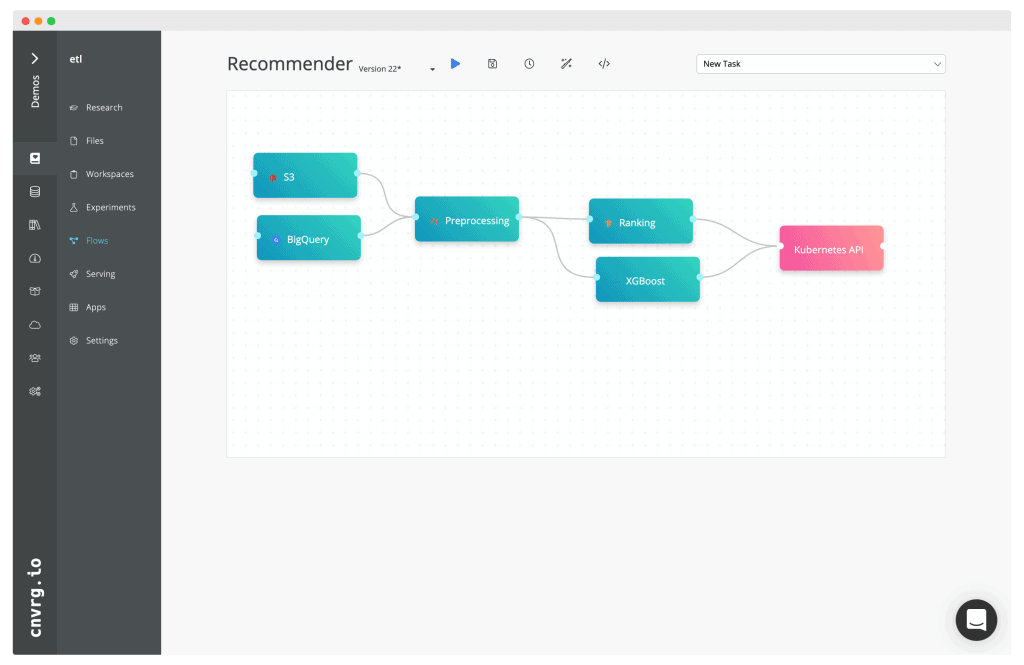
Build a recommendation system with Deep Learning and Kubernetes
Combine data from S3 and BigQuery, preprocess using Spark on Kubernetes and use TensorFlow Ranking/XGBoost to build a recommendation system and deploy it as a REST API on Kubernetes
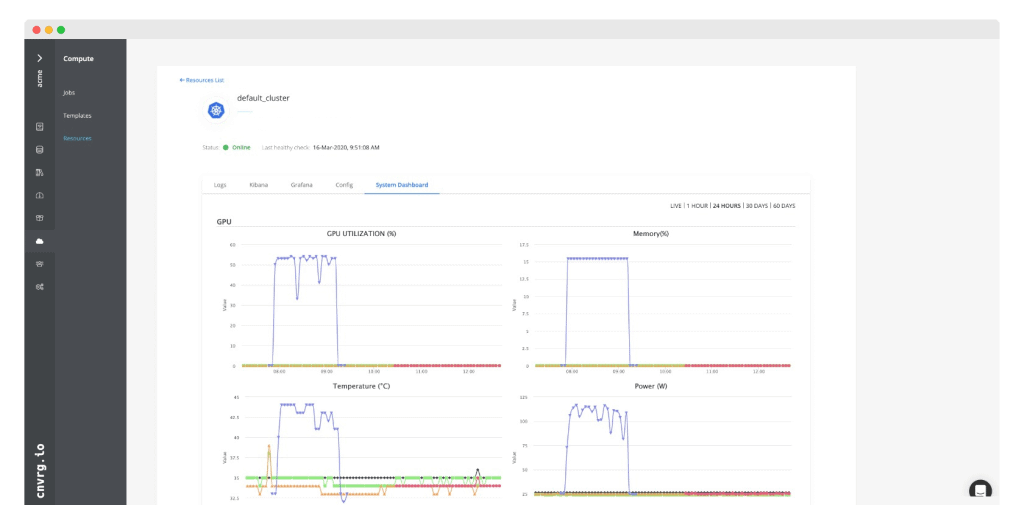
Manage resources and increase utilization with CPU/GPU dashboards
Connect all your GPUs, CPUs and compute resources to a single, unified environment (with cloud-bursting built-in) - monitor and see in-depth analysis of usage, utilization and consumption of compute in your ML workloads
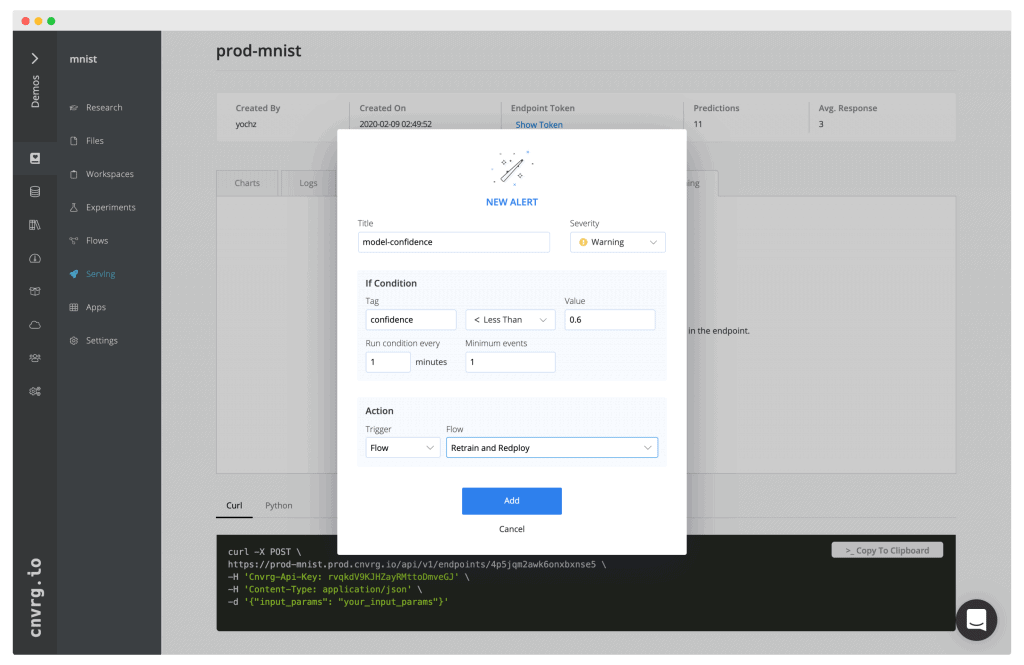
Track & monitor predictions in production and trigger alerts/retraining
Automatically log all predictions in a scalable and Kubernetes-based environment, use cnvrg.io to monitor each sample; both input and prediction. Identify anomalies, monitor model decay, data correlation and trigger retraining/alerts automatically
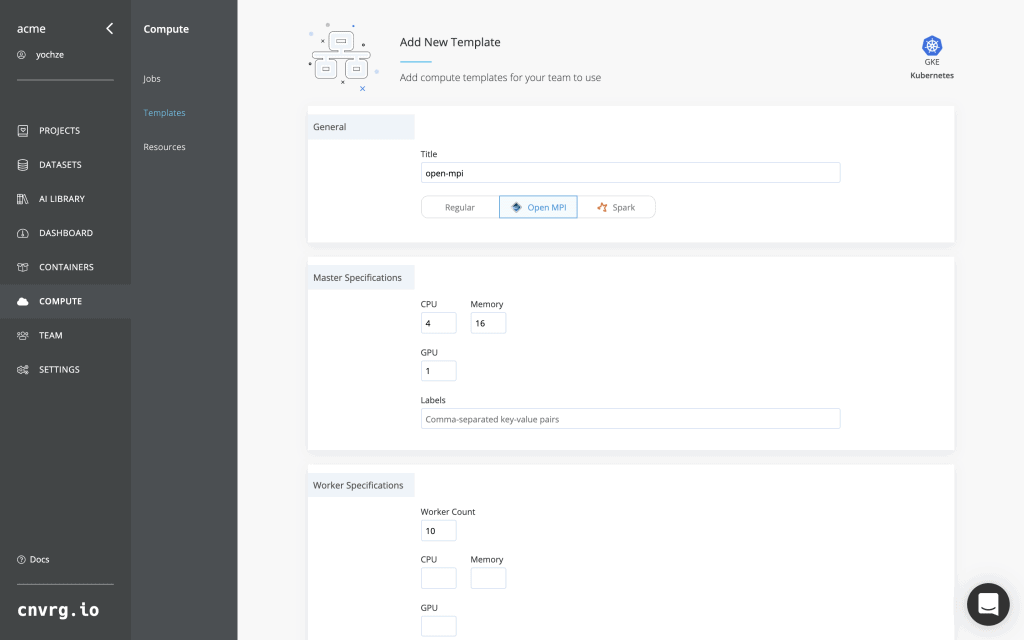
Launch OpenMPI, Horovod and distributed deep-learning jobs in a single click
Launch OpenMPI jobs on any multi-node Kubernetes cluster (cloud/on-prem) in a single click. Use the built-in Kubeflow MPI operator to run your Horovord / TensorFlow distributed training and track performance in real-time using the cnvrg.io dashboard