


Regression problem is considered one of the most common Machine Learning (ML) tasks. There are various approaches, for example, using a standalone model of the Linear Regression or the Decision Tree. However, if you work with a single model you will probably not get any good results.
Let’s look at the Decision Trees case. As you might know, they can reconstruct very complex patterns but tend to underperform if even minor changes in the data occur. That’s why a standalone Decision Tree will not obtain great results. Still, if you compose plenty of these Trees the predictive performance will improve drastically. Today you will learn how to solve a Regression problem using an ensemble method called Random Forest.
In this article we will talk about:
- What is Ensemble Learning?
- Ensemble Learning, Ensemble model, Boosting, Stacking, Bagging
- Random Forest
- Random Forest for Regression and Classification, algorithm, advantages and disadvantages, Random Forest vs. other algorithms
- Training, tuning, testing, and visualizing Random Forest Regressor
- When to use Random Forest
- Best practices, tips, and strategies
Let’s jump in.
What is Ensemble Learning?
The general idea of ensemble learning is quite simple. You should train multiple ML algorithms and combine their predictions in some way. Such an approach tends to make more accurate predictions than any individual model. An Ensemble model is a model that consists of many base models.
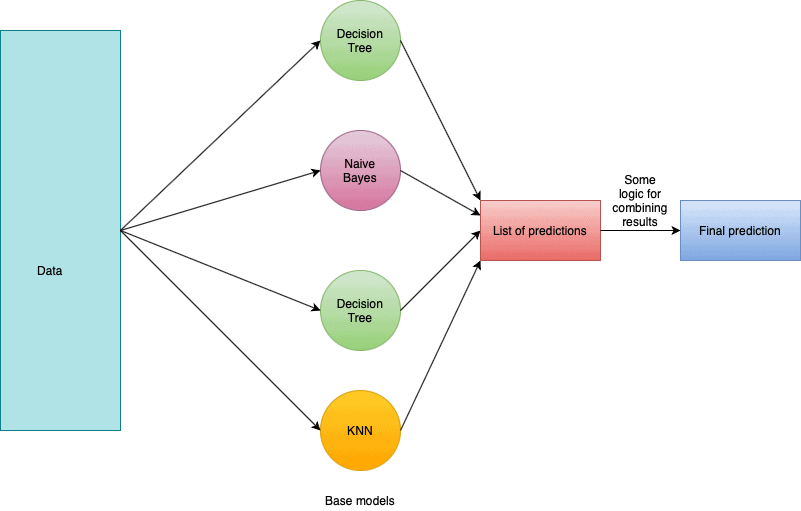
So, ensemble learning is a process where multiple ML models are generated and combined to solve a particular problem. In general, ensemble learning is used to obtain better performance results and reduce the likelihood of selecting a poor model.
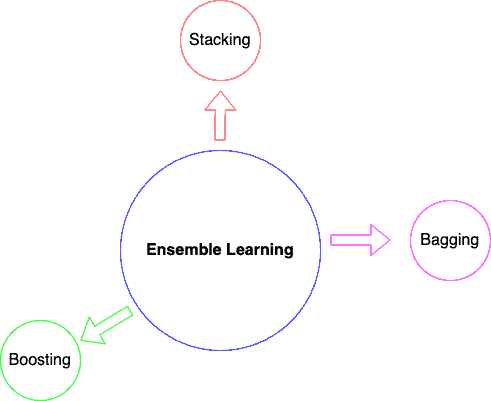
Types of Ensemble Learning
There are various ensemble learning types:
- Sequential Ensemble Learning (Boosting)
- Parallel Ensemble Learning (Bootstrap Aggregating => Bagging)
- Stacking
- And others (less commonly used)
Boosting
As mentioned above, boosting uses the sequential approach. The key idea of the boosting algorithm is incrementally building an ensemble by training each new model instance to emphasize the training instances that previous models misclassified. So, one model is learning from the mistakes of another which boosts the learning.
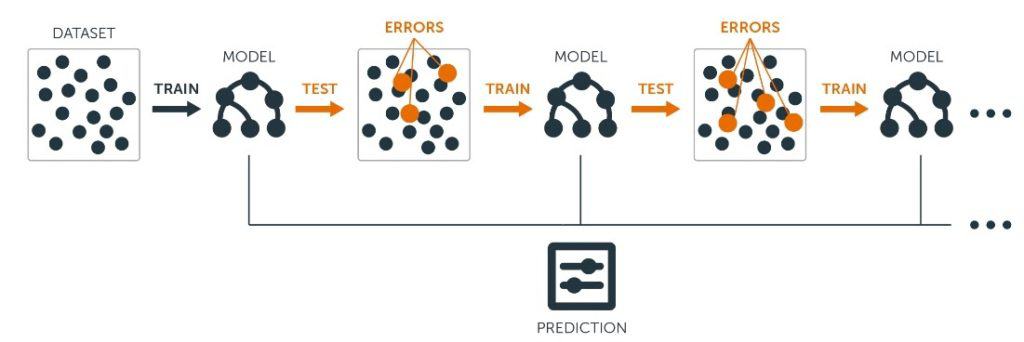
In general, boosting is a strong and widely used technique. Unfortunately, it tends to overfit the training data, so you need to be careful when using it. Nevertheless, there are many boosting algorithms, for example, AdaBoost, Stochastic Gradient Boosting, XGBoost, CatBoost, and others.
Stacking
In my opinion, stacking is a slightly more interesting technique. It involves training a model (called the Meta Learner) to combine predictions of multiple other Machine learning algorithms (Base Learners).
First, Base Learners are trained using the available data. Second, the Meta Learner is trained to make a final prediction using the Base Learners’ predictions as the input data.
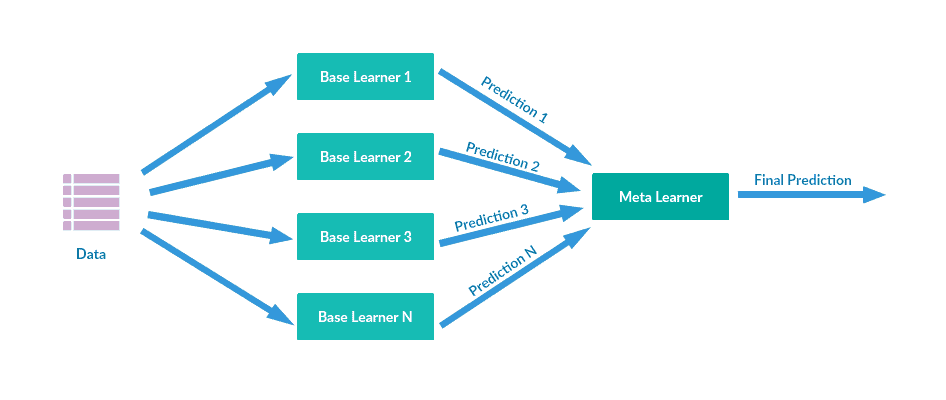
Stacking obtains better performance results than any of the individual algorithms. It can be used to successfully solve both supervised and unsupervised ML problems. For example, you can use stacking for the regression and density estimation task.
Bagging
It is worth mentioning that Bootstrap Aggregating or Bagging is a pretty simple yet really powerful technique. Understanding the general concept of Bagging is really crucial for us as it is the basis of the Random Forest (RF) algorithm. Let’s check the general Bagging algorithm in depth.
- To start with, let’s assume you have some original data that you want to use as your training set (dataset D). You want to have K base models in our ensemble.
- In order to promote model variance, Bagging requires training each model in the ensemble on a randomly drawn subset of the training set. The number of samples in each subset is usually as in the original dataset (for example, N), although it can be smaller.
- To create each subset you need to use a bootstrapping technique:
- First, randomly pull a sample from your original dataset D and put it to your subset
- Second, return the sample to D (this technique is called sampling with replacement)
- Third, perform steps a and b N (or less) times to fill your subset
- Then perform steps a, b, and c K – 1 time to have K subsets for each of your K base models
- Build each of K base models on its subset
- Combine your models and make the final prediction
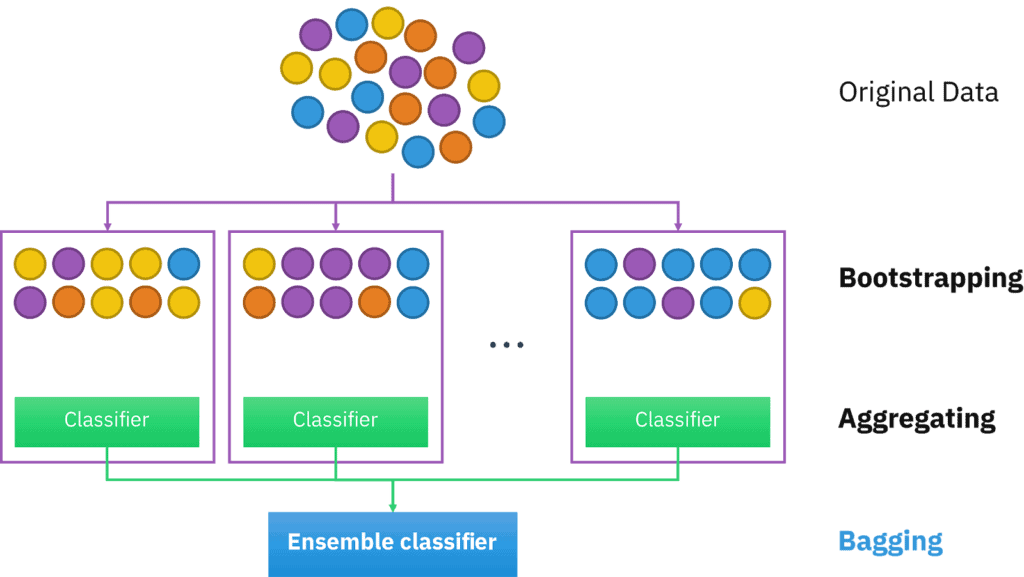
If you are solving a Classification problem, you should use a voting process to determine the final result. The result is usually the most frequent class among K model predictions. In the case of Regression, you should just take the average of the K model predictions. Still, please remember that your combining logic might differ from the one presented in this article. However, you must stay logical when playing with it.
Overall, Bagging is a nice technique that helps to handle overfitting and reduce variance.
Random Forest
Now you understand the basics of Ensemble Learning. You also know what major types of Ensemble Learning there are and what Bagging is in depth. Now let’s move on and discuss the Random Forest algorithm. This section will cover using Random Forest to solve a Regression task. I will try to be as precise as possible and try to cover every aspect you might need when using RF as your algorithm for an ML project.
What will be covered in this section:
- What is Random Forest?
- When to use Random Forest
- Advantages and disadvantages
- How to use Random Forest for Regression?
- Random Forest Vs. other algorithms
Let’s jump in.
What is Random Forest?
Random Forest is a Supervised learning algorithm that is based on the ensemble learning method and many Decision Trees. Random Forest is a Bagging technique, so all calculations are run in parallel and there is no interaction between the Decision Trees when building them. RF can be used to solve both Classification and Regression tasks.
The name “Random Forest” comes from the Bagging idea of data randomization (Random) and building multiple Decision Trees (Forest). Overall, it is a powerful ML algorithm that limits the disadvantages of a Decision Tree model (we will cover that later on). Moreover, Random Forest is quite popular as can be seen through many Kaggle competitions, academic papers, and technical posts.
Random Forest Algorithm
To make things clear let’s take a look at the exact algorithm of the Random Forest:
- So, you have your original dataset D, you want to have K Decision Trees in our ensemble. Additionally, you have a number N – you will build a Tree until there are less or equal to N samples in each node (for the Regression, task N is usually equal to 5). Moreover, you have a number F – number of features that will be randomly selected in each node of the Decision Tree. The feature that will be used to split the node is picked from these F features (for the Regression task, F is usually equal to sqrt(number of features of the original dataset D)
- Everything else is rather simple. Random Forest creates K subsets of the data from the original dataset D. Samples that do not appear in any subset are called “out-of-bag” samples.
- K trees are built using a single subset only. Also, each tree is built until there are fewer or equal to N samples in each node. Moreover, in each node F features are randomly selected. One of them is used to split the node
- K trained models form an ensemble and the final result for the Regression task is produced by averaging the predictions of the individual trees
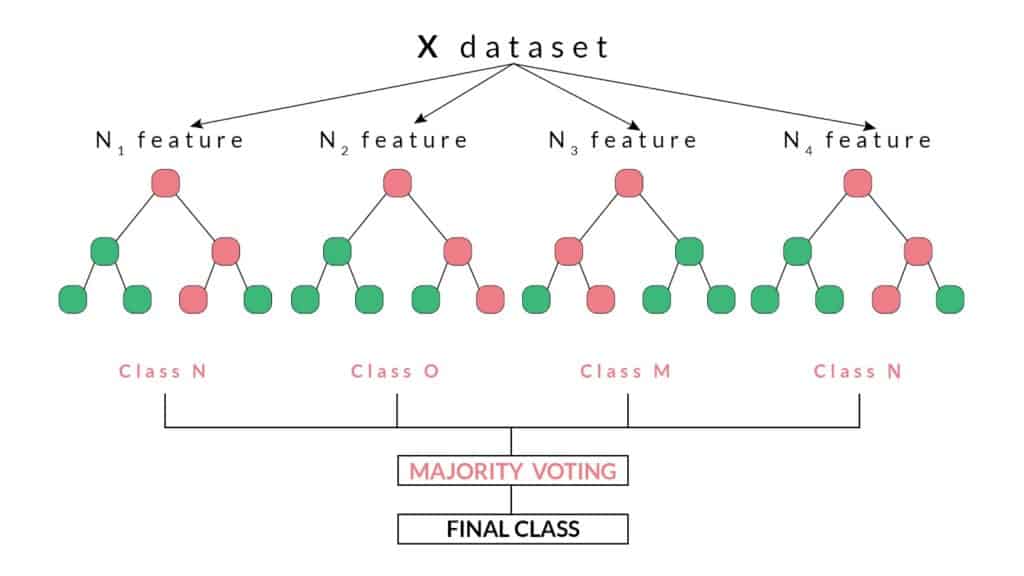
In the picture below you might see the Random Forest algorithm for Classification.
Advantages and disadvantages
To start with, let’s talk about the advantages. Random Forest is based on the Bagging technique that helps to promote the algorithm’s performance. Random Forest is no exception. It works well “out-of-the-box” with no hyperparameter tuning and way better than linear algorithms which makes it a good option. Moreover, Random Forest is rather fast, robust, and can show feature importances which can be quite useful.
Also, Random Forest limits the greatest disadvantage of Decision Trees. It almost does not overfit due to subset and feature randomization. Firstly, it uses a unique subset of the initial data for every base model which helps to make Decision Trees less correlated. Secondly, it splits each node in every Decision Tree using a random set of features. Such an approach means that no single tree sees all the data, which helps to focus on the general patterns within the training data, and reduces sensitivity to noise.
Nevertheless, Random Forest has disadvantages. Despite being an improvement over a single Decision Tree, there are more complex techniques than Random Forest. To tell the truth, the best prediction accuracy on difficult problems is usually obtained by Boosting algorithms.
Also, Random Forest is not able to extrapolate based on the data. The predictions it makes are always in the range of the training set. It is a major disadvantage as not every Regression problem can be solved using Random Forest. The Random Forest Regressor is unable to discover trends that would enable it in extrapolating values that fall outside the training set. Actually, that is why Random Forest is used mostly for the Classification task.
Moreover, Random Forest is less interpretable than a Decision tree. Single trees may be visualized as a sequence of decisions while RF cannot. It might make it a bit confusing. It is worth mentioning that a trained RF may require significant memory for storage as you need to retain the information from several hundred individual trees.
Overall, Random Forest is one of the most powerful ensemble methods. In practice, it may perform slightly worse than Gradient Boosting, but it is also much easier to implement. You should definitely try it for a Regression task if the data has a non-linear trend and extrapolation outside the training data is not important. Still, if your problem requires identifying any sort of trend you must not use Random Forest as it will not be able to formulate it.
Let’s discuss a more practical application of Random Forest.
When to use Random Forest in real life
As mentioned above, Random Forest is used mostly to solve Classification problems. It is worth noting that Random Forest is rarely used in production simply because of other algorithms showing better performance. However, RF is a must-have algorithm for hypothesis testing as it may help you to get valuable insights. For example, the “out-of-the-box” Random Forest model was good enough to show a better performance on a difficult Fraud Detection task than a complex multi-model neural network.
From my experience, you might want to try Random Forest as your ML Classification algorithm to solve such problems as:
- Fraud Detection (Classification) – please refer to the article I linked above. You may find it pretty thrilling as it shows how simple ML models can beat complex neural networks on an unobvious task
- Credit Scoring (Classification) – an important solution in the banking sector. Some banks build enormous neural networks to improve this task. However, simple approaches might give the same result
- E-commerce case (Classification) – for example, we can try to predict if the customer will like the product or not
- Any Classification problem with a table data, for example, Kaggle competitions
In the Regression case, you should use Random Forest if:
- It is not a time series problem
- The data has a non-linear trend and extrapolation is not crucial
For example, Random Forest is frequently used in value prediction (value of a house or a packet of milk from a new brand).
It is time to move on and discuss how to implement Random Forest in Python.
How to use Random Forest for Regression
For this section I have prepared a small Google Collab notebook for you featuring working with Random Forest, training on the Boston dataset, hyperparameter tuning using GridSearchCV, and some visualizations. Please feel free to experiment and play around as there is no better way to master something than practice.
Setting up
As mentioned above it is quite easy to use Random Forest. Fortunately, the sklearn library has the algorithm implemented both for the Regression and Classification task. You must use RandomForestRegressor() model for the Regression problem and RandomForestClassifier() for the Classification task.
If you do not have the sklearn library yet, you can easily install it via pip. Also, please keep in mind that sklearn updates regularly, so you should keep track of that as you want to use only the newest versions of the library (it is the 0.24.0 version as of today).
!pip install -U scikit-learn If you have everything installed you can easily import the RandomForestRegressor model from sklearn, assign it to the variable and start working with it.
from sklearn.ensemble import RandomForestRegressor
random_forest = RandomForestRegressor() Training
If you have ever trained a ML model using sklearn you will have no difficulties working with the RandomForestRegressor. All you need to do is to perform the fit method on your training set and the predict method on the test set.
random_forest.fit(X_train, y_train)
y_pred = random_forest.predict(X_test) However, Random Forest in sklearn does not automatically handle the missing values. The algorithm will return an error if it finds any NaN or Null values in your data. If you want to check it for yourself please refer to the “Missing values” section of the notebook. Of course, you may easily drop all the samples with the missing values and continue training. Still, there are some non-standard techniques that will help you overcome this problem (you may find them in the “Missing value replacement for the training set” and ”Missing value replacement for the test set” sections of the documentation).
Overall, please do not forget about the EDA. It is always better to study your data, normalize it, handle the categorical features and the missing values before you even start training. That way you will be able to avoid many obstacles.
Tuning
In general, you should always tune your model as it must help to enhance the algorithm’s performance. As you might know, tuning is a really expensive process time-wise. When tuning a Random Forest model it gets even worse as you must train hundreds of trees multiple times for each parameter grid subset. So, you must not be afraid. Trust me, it is worth it.
You can easily tune a RandomForestRegressor model using GridSearchCV. If you are not sure what model hyperparameters you want to add to your parameter grid, please refer either to the sklearn official documentation or the Kaggle notebooks. Sklearn documentation will help you find out what hyperparameters the RandomForestRegressor has. Kaggle notebooks, on the other hand, will feature parameter grids of other users which may be quite helpful.
andom_forest_tuning = RandomForestRegressor(random_state = SEED)
param_grid = {
'n_estimators': [100, 200, 500],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth' : [4,5,6,7,8],
'criterion' :['mse', 'mae']
}
GSCV = GridSearchCV(estimator=random_forest_tuning, param_grid=param_grid, cv=5)
GSCV.fit(X_train, y_train)
GSCV.best_params_ Testing
When you have your model trained and tuned, it is time to test its final performance. Random Forest is just another Regression algorithm, so you can use all the regression metrics to assess its result.
For example, you might use MAE, MSE, MASE, RMSE, MAPE, SMAPE, and others. However, from my experience, MAE and MSE are the most commonly used. Both of them will be a good fit to evaluate the model’s performance. So, if you use them, keep in mind that the less is your error, the better and the error of the perfect model will be equal to zero.
random_forest = RandomForestRegressor(random_state = SEED)
random_forest.fit(X_train, y_train)
y_pred = random_forest.predict(X_test)
print('MAE: ', mean_absolute_error(y_test, y_pred))
print('MSE: ', mean_squared_error(y_test, y_pred)) Also, it is worth mentioning that you might not want to use any Cross-Validation technique to check the model’s ability to generalize. Some Data Scientists think that the Random Forest algorithm provides free Cross-Validation. You see, Random Forest randomizes the feature selection during each tree split, so that it does not overfit like other models. That is why using Cross-Validation on the Random Forest model might be unnecessary.
Still, if you want to use the Cross-Validation technique you can use the hold-out set concept. As mentioned before, samples from the original dataset that did not appear in any subset are called “out-of-bag” samples. They are a perfect fit for the hold-out set. Generally, using “out-of-bag” samples as a hold-out set will be enough for you to understand if your model generalizes well.
In sklearn, you can easily perform that using an oob_score = True parameter. If set to True, this parameter makes Random Forest Regressor use “out-of-bag” samples to estimate the R^2 on unseen data. If you get a value of more than 0.75, it means your model does not overfit (the best possible score is equal to 1)
random_forest_out_of_bag = RandomForestRegressor(oob_score=True)
random_forest_out_of_bag.fit(X_train, y_train)
print(random_forest_out_of_bag.oob_score_) Visualizing
It is crucial to have some valuable visualizations to your model. It will be easier for you to present the results if you have some simple graphs. Also, it is quite easy to do.
For example, you can visualize the model’s predictions. In the picture below the real values are plotted with red color and the predicted are plotted with green.
plt.scatter(X_test['RM'].values, y_test, color = 'red')
plt.scatter(X_test['RM'].values, y_pred, color = 'green')
plt.title('Random Forest Regression')
plt.xlabel('RM')
plt.ylabel('Price')
plt.show() 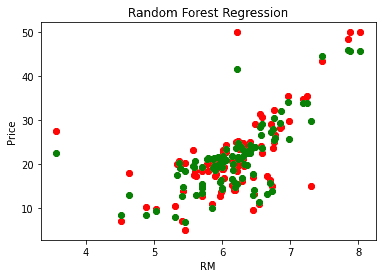
Also, you can plot any tree from the ensemble. For the picture please refer to the “Visualizations” section of the notebook.
from sklearn import tree
fn=data.feature_names
cn=data.target
fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (4,4), dpi=800)
tree.plot_tree(random_forest.estimators_[0],
feature_names = fn,
class_names=cn,
filled = True);
You can come up with other valuable visualizations yourself or check Kaggle for some ideas. Still, please remember that your visualization must be easy to interpret to be effective.
Random Forest vs. other algorithms
Overall, Random Forest is one of the most powerful ensemble methods. It can be used both for Classification and Regression and has a clear advantage over linear algorithms such as Linear and Logistic Regression and their variations. Moreover, a Random Forest model can be nicely tuned to obtain even better performance results.
However, Random Forest is not perfect and has some limitations. As mentioned before you should not use Random Forest when having data with different trends. Also, Boosting algorithms tend to perform better than the Random Forest. That is why I have formed some sort of a general ML project workflow to help you work effectively.
- Make a naive model. For example, simply take a median of your target and check the metric on your test data. Do not use any ML algorithms, just work with your data and see if you find some insights. Check if you can use other ML algorithms such as Random Forest to solve the task
- Use a linear ML model, for example, Linear or Logistic Regression, and form a baseline
- Use Random Forest, tune it, and check if it works better than the baseline. If it is better, then the Random Forest model is your new baseline
- Use Boosting algorithm, for example, XGBoost or CatBoost, tune it and try to beat the baseline
- Choose the model that obtains the best results
Thus, sometimes it is hard to tell which algorithm will perform better. You must explore your options and check all the hypotheses. It will help you to dive deeply into the task and solve it more efficiently. From my experience, Random Forest is definitely an algorithm you should keep an eye on when solving a Regression task.
Best practices, tips, and strategies
Throughout this article I mentioned plenty of useful tips and techniques, so let’s summarize them into a list:
- Use ensemble models to obtain better performance
- Explore the types of Ensemble Learning besides Boosting, Stacking, and Bagging
- Boosting tends to be the most powerful Ensemble Learning technique
- Random Forest is based on the Bagging technique
- Random Forest Regressor should be used if the data has a non-linear trend and extrapolation outside the training data is not important
- Random Forest Regressor should not be used if the problem requires identifying any sort of trend
- It is really convenient to use Random Forest models from the sklearn library
- Always tune Random Forest models
- Use any Regression metric to evaluate your Random Forest Regressor model
- Do not forget that Cross-Validation might be unnecessary
- Always visualize your results and make them easy to interpret
- Explore your options and check all the hypothesis when choosing a ML model
- Do not forget about the EDA
- Use a nice model management and experiment tracking tool. For example, cnvrg.io is a powerful tool and has a scikit-learn integration
Final Thoughts
Hopefully, this tutorial will help you succeed and use the Random Forest algorithm in your next Machine Learning project.
To summarize, we started with some theoretical information about Ensemble Learning, ensemble types, Bagging and Random Forest algorithms and went through a step-by-step guide on how to use Random Forest in Python for the Regression task. Also, we compared Random Forest with some other ML Regression algorithms. Lastly, we talked about some tips you may find useful when working with Random Forest.
If you enjoyed this post, a great next step would be to start building your own Machine Learning project with all the relevant tools. Check out tools like:
- Random Forest Regressor as a ML model,
- cnvrg.io for model management and experiment tracking
For extra support, you can access the Notebook for further code and documentation.
Thanks for reading, and happy training!







