

What’s the state of Machine Learning at the end of 2021?
What is ML Insider?
The ML Insider is cnvrg.io’s annual survey of the Machine Learning industry highlighting key trends, points of interest, and challenges that AI developers experience. This report offers insights into how over 290 ML professionals are building, training, deploying and adapting their machine learning stack to better suit today’s modern, complex ML workflow.
About us
cnvrg.io is a full stack machine learning operating system with everything an AI developer needs to build and deploy AI on any infrastructure. cnvrg.io was built by data scientists, for data scientists to streamline the machine learning process, so they can focus on the data science work they’d rather be doing instead of the operational complexity of managing machine learning pipelines.
Background
Enterprises have an increasing appetite for faster time to insight. However, getting value from AI is hard as projects take too long to deliver value, if they’re delivered at all. According to recent Gartner research, barely a majority of projects go from the lab to production, and even then it takes about nine months on average.
To gain a better understanding of the adoption and usage of machine learning in their organizations, cnvrg.io conducted a survey of professionals involved with data science across industries and organizations.
So what’s our overall takeaway? Most of our survey respondents indicated that they have
- Small data science and DevOps teams
- Limited end-to-end automation of ML pipelines
- Only a limited number of experiments running
The survey results, backed by discussions with our own customers, is that there is an opportunity to automate more of the ML pipeline, and that increasing automation will drive more experiments, help amplify the work of small teams, and lead to increasing value from data science.
Who took this survey?
The survey covered 290 participants, representing organizations in size from a few employees to over 5,000 (about 33% of the respondents came from enterprises with over 5,000 employees), as shown in Figure 1 below. The insights from the survey covered dozens of industries; among the most common were: software development, financial services, health care, higher education, information technology and services besides software, telecommunications, and media.
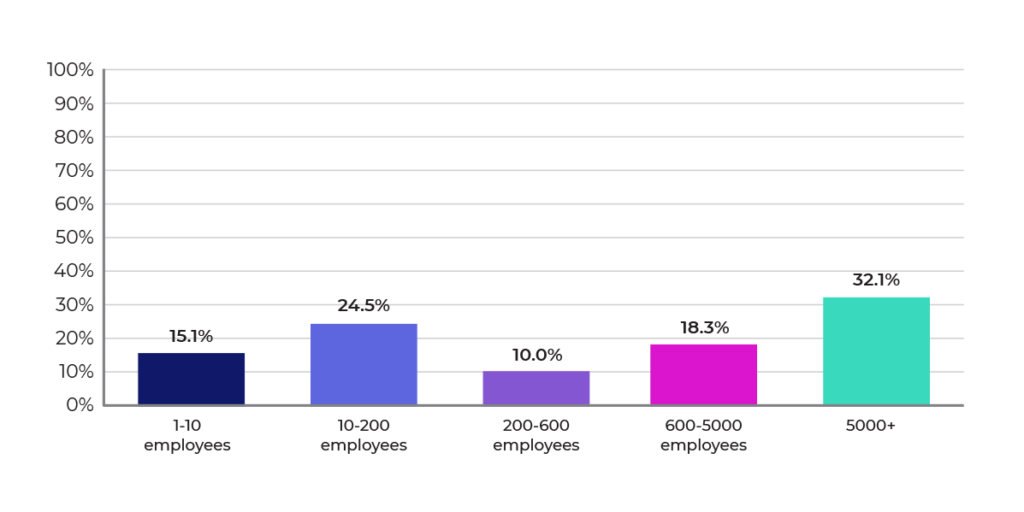
Figure 1: Size of Organization
Almost two-thirds of the respondents indicated that their professional role involved model development (data scientist: 42%) or putting models into production (ML engineer: 22%) Figure 2.
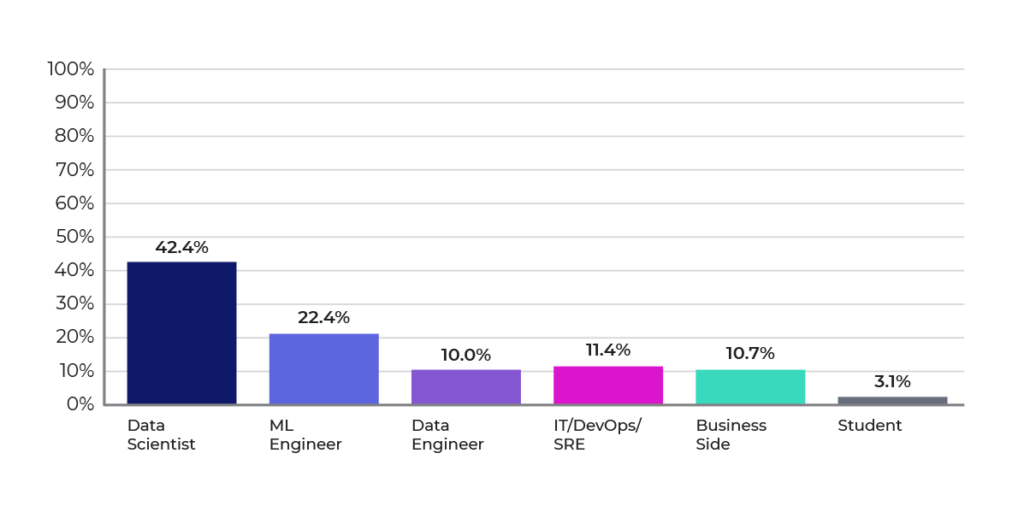
Figure 2: Professional roles
As shown in Figure 3, the most common educational attainment was at the Masters’ level. Interestingly, lesser-skilled individuals at the Bachelor level, or even having only a few courses in machine learning (almost 30% of the respondents) are contributing to their organizations’ data science programs. Easy-to-use software tooling that can meet the needs of these team members will become increasingly important as enterprises seek to use ML in their products and services.
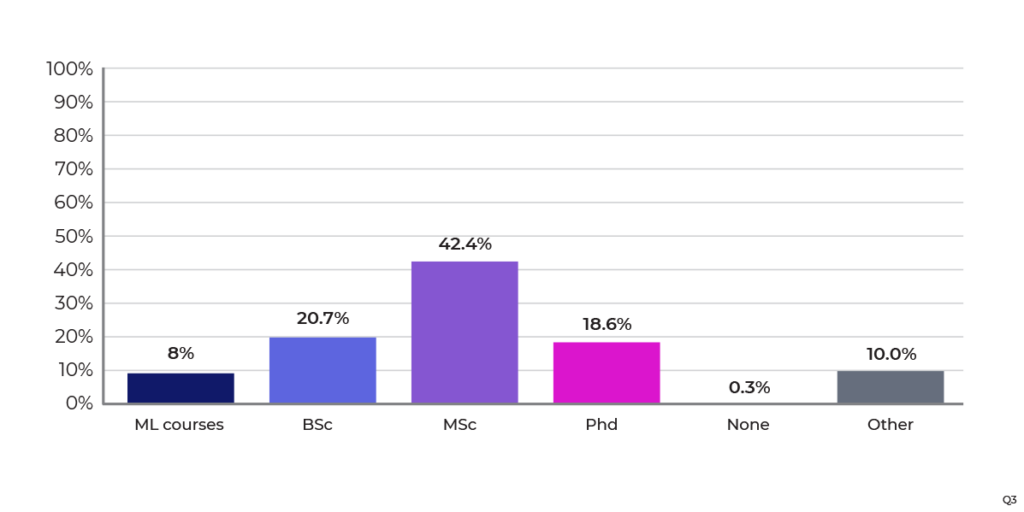
Figure 3: Education level
Level of ML experience in organizations
As Figures 4 and 5 show, most respondents tended to have small ML and DevOps teams. About a third of the companies have data-science and DevOps teams of five or less. It’s hard for small teams to develop and manage enterprise-scale ML initiatives. Automation will become increasingly important to multiply the effectiveness of small teams in order to scale out ML in the enterprise.
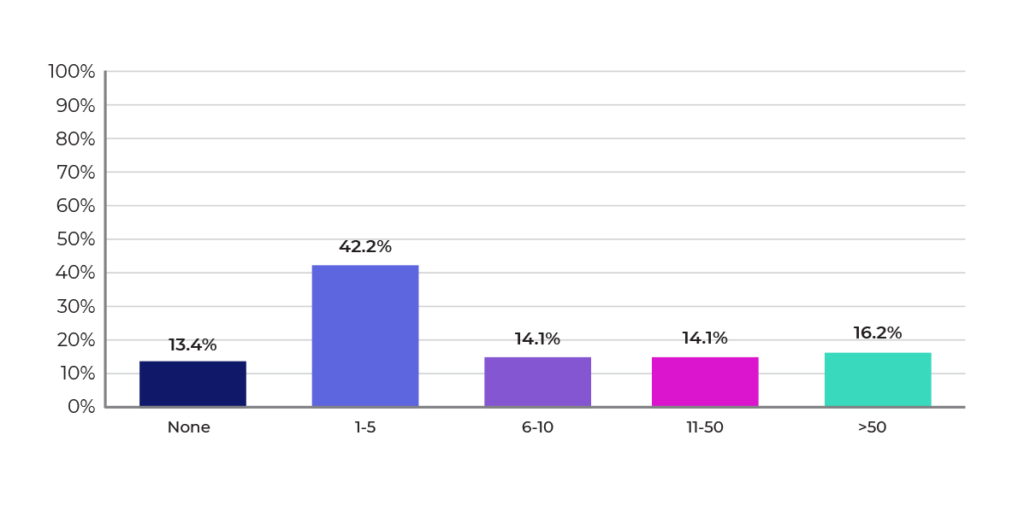
Figure 4: Size of ML engineering team
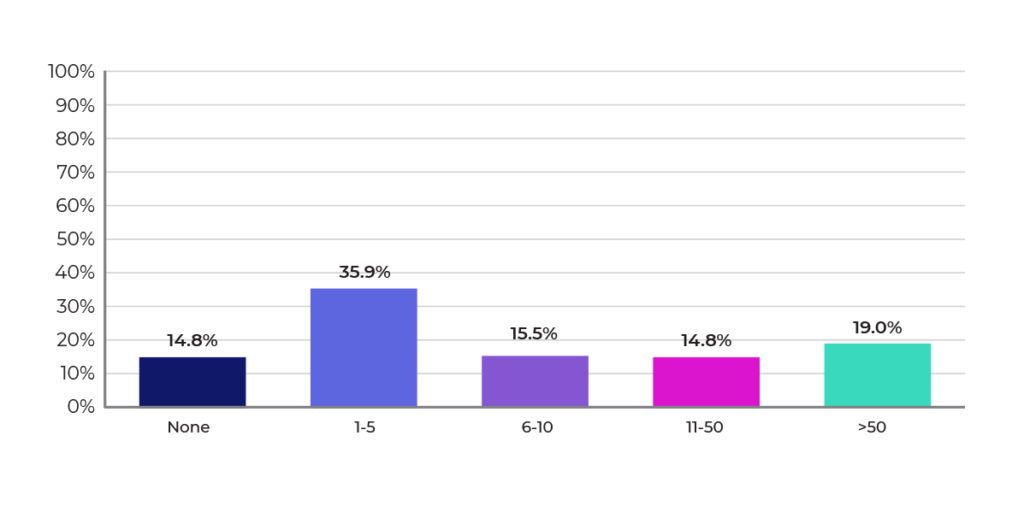
Figure 5: Size of the DevOps team
Figure 6 below shows that difficulty in recruiting talent continues to be a major inhibitor of ML success. Most respondents indicated that lack of knowledge and expertise on their teams was their main challenge. When combined with the fact that teams tend to be small anyway, difficulty in obtaining talent points to the need for getting the most out of what talent is already there. Automation for data science experts, and bringing more user-friendly, low code tools to the rest of the organization, should help alleviate these challenges.
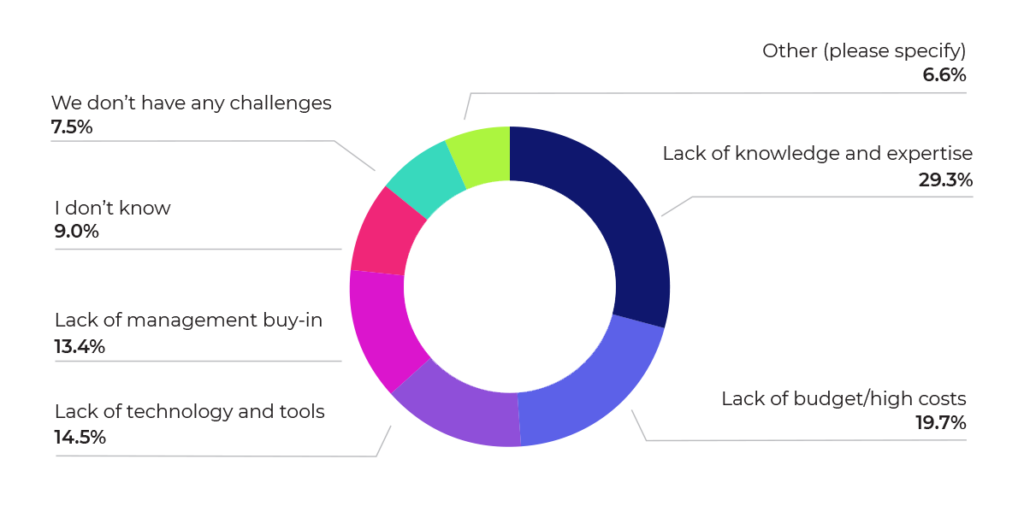
Figure 6: What is your or your company’s main challenge in executing ML programs?
Unsurprisingly, most organizations run their ML experiments in the cloud (Figure 7), reflecting the easy, self-service nature of cloud computing. However, the chart indicates that on prem and hybrid architectures are still significant, indicating thatMLOps solutions still need to cover a variety of training and deployment scenarios.
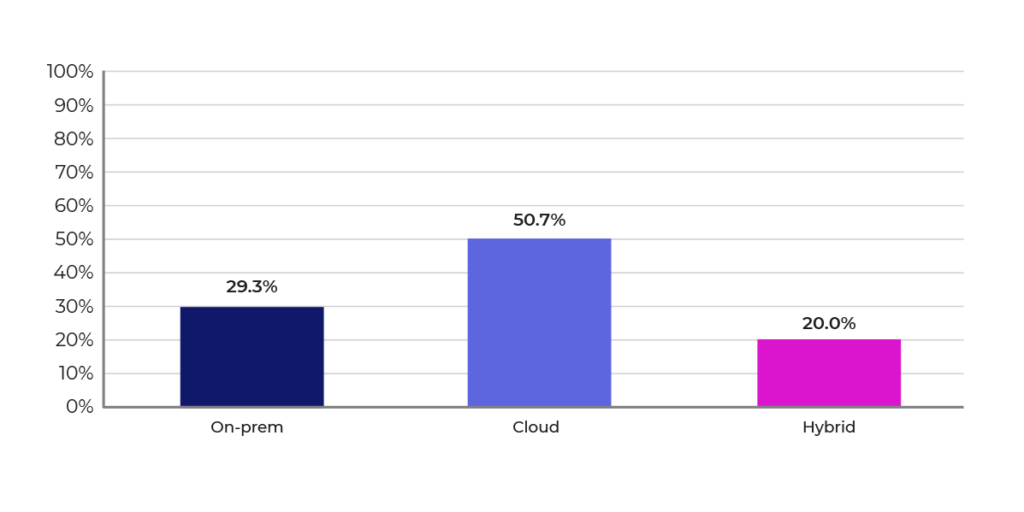
Figure 7: Where do you run your ML experiments?
Figures 8, 9, and 10 highlight the need and opportunities for automation. Most respondents aren’t using AutoML solutions, and also most are running only 1-30 experiments per month. Almost 60% of the survey respondents indicated that there is some automation of tasks, but that leaves opportunities to increase the overall level of automation. Increasing automation will unlock the number of experiments that organizations can perform, which should lead to better ROI from their data science efforts.

Figure 8: How many ML experiments did you or your company run in the last month?
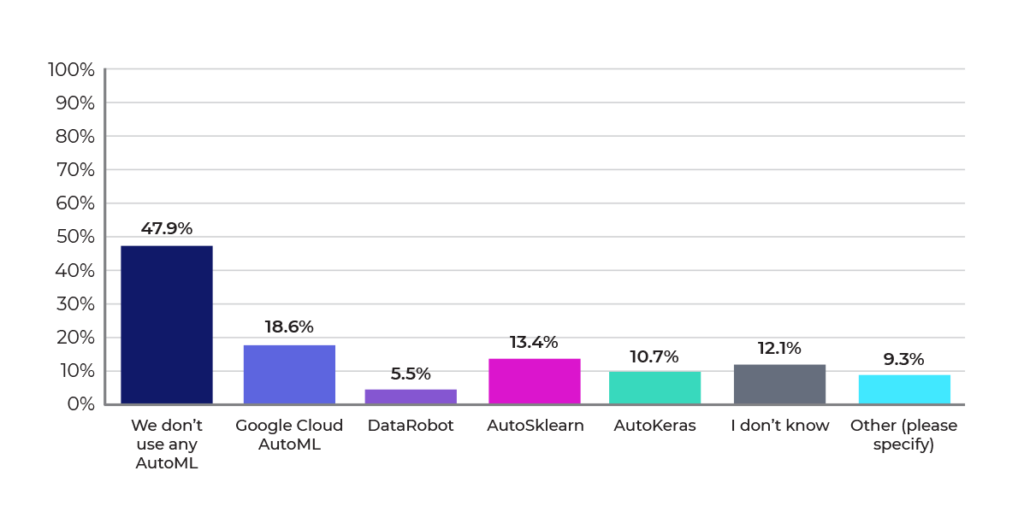
Figure 9: What AutoML solutions are you using?
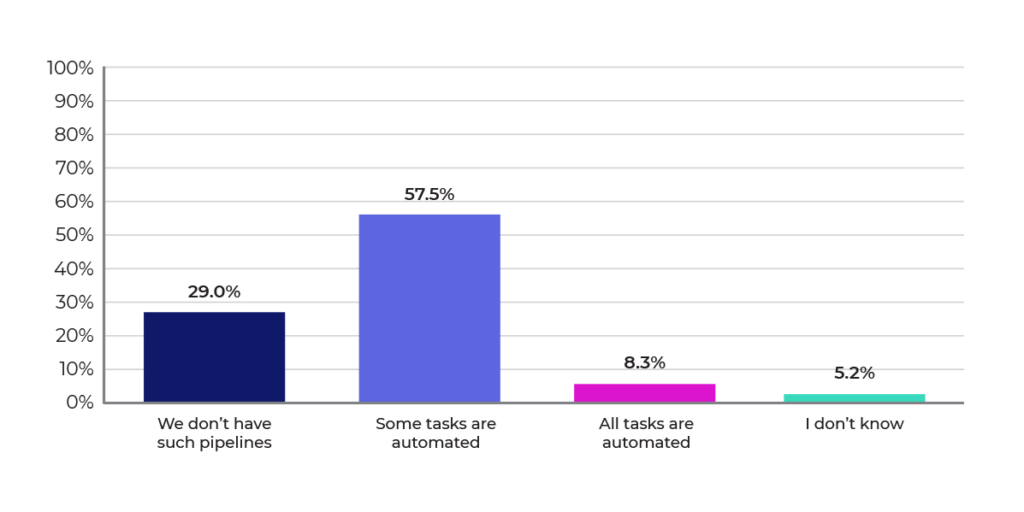
Figure 10: How mature are your research-to-production automated pipelines?
Figure 11 shows that data-oriented tasks (acquisition and cleansing) continue to be the most difficult for data scientists to address. Not coincidentally, these also tend to be the tasks that data scientists dislike the most and take the most time. Improving automation in these areas is likely to yield better results from the data science program and improve the quality of life for data science professionals.
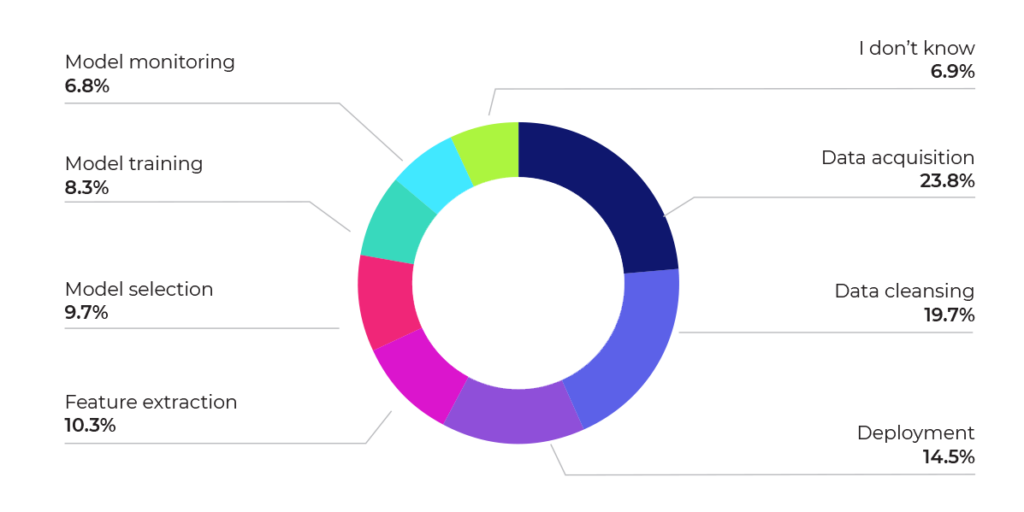
Figure 11: Which phase of the ML pipeline would you consider to be most challenging?
Emerging trends in ML frameworks and libraries
As Figure 12 shows, after taking the DevOps world by storm, Kubernetes is increasingly important to machine learning. Over 60% of respondents indicated that they are using Kubernetes at some level in their ML workflows.
This is unsurprising, as containerization and Kubernetes promote agile model development and deployment. Containers simplify packaging libraries and applications for rapid model deployments that include frequent model builds, quick software releases, and rollbacks. Additionally, containers enable consistency across the ML pipeline. Kubernetes in turn simplifies the burden of orchestrating and managing containers.
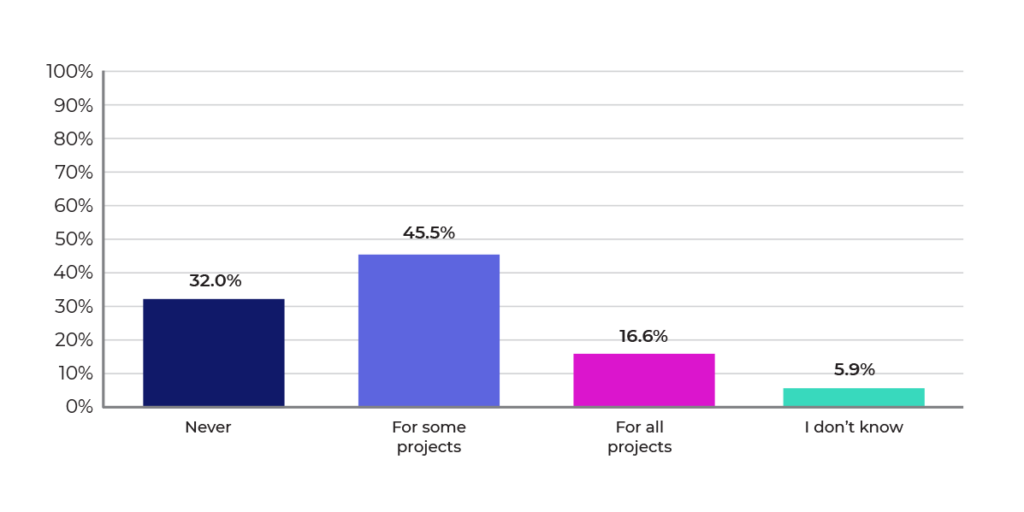
Figure 12: Are you using Kubernetes for ML tasks?
In nearly every survey of popular ML frameworks, TensorFlow, PyTorch, scikit-learn, and
Spark ML are at or near the top every time. That is also borne out by our survey, where scikit-learn, TensorFlow, and PyTorch take top honors among our respondents, as shown in Figure 13. Figure 14 shows the most popular languages used. Consistent with other surveys, Python and R remain the leading programming languages in data science, with Python reigning supreme.
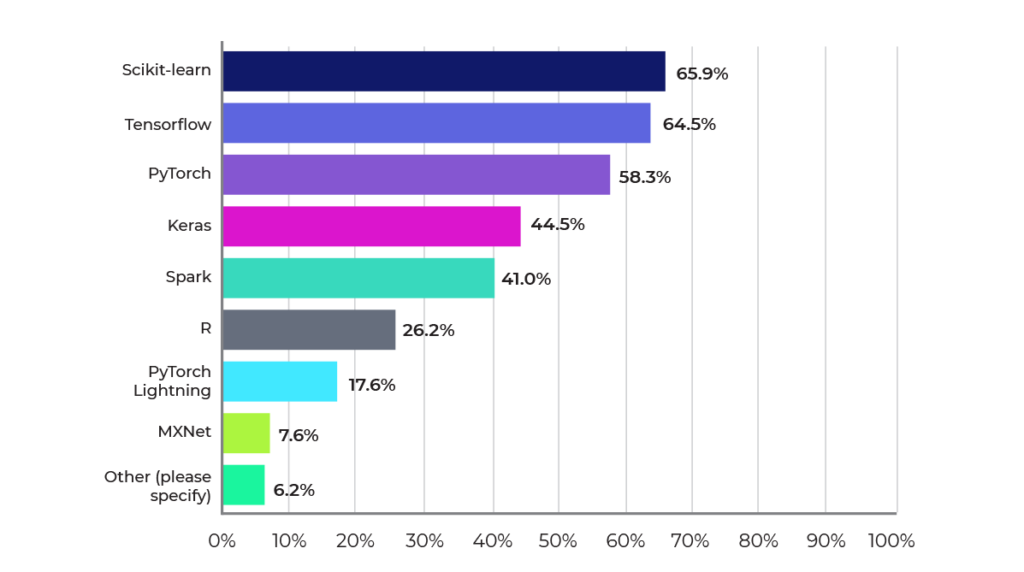
Figure 13: Most popular frameworks for machine learning
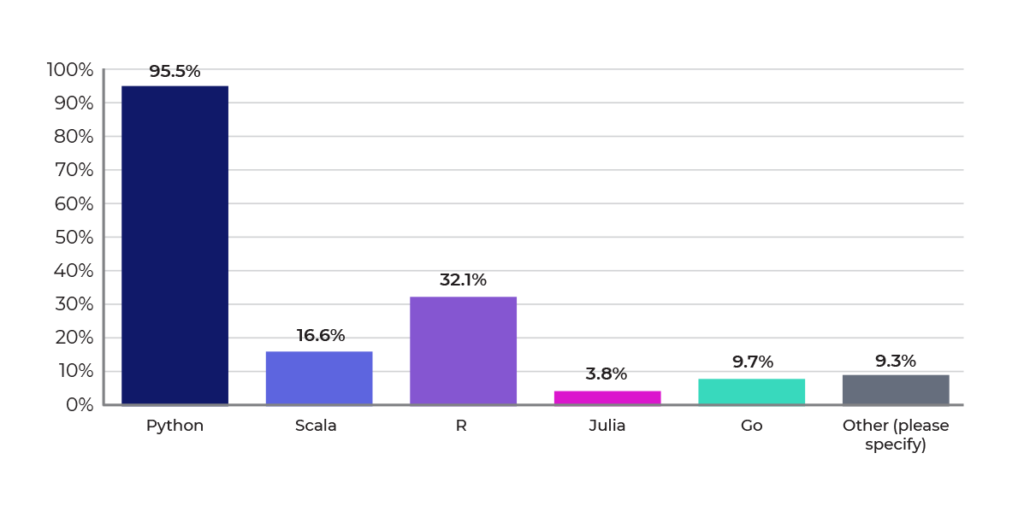
Figure 14: Most popular languages for machine learning
Summary
Are you looking for a way to automate your own ML operations? The cnvrg.io Metacloud managed platform offers automation of your end-to-end ML pipelines. It also gives developers the ability to take advantage of their own compute and storage, as well as a marketplace of native integrations to the resources provided by major clouds and leading OEMs. It removes the operational complexity of training and deploying models into production. Learn more about cnvrg.io Metacloud, and sign up to get started in minutes!