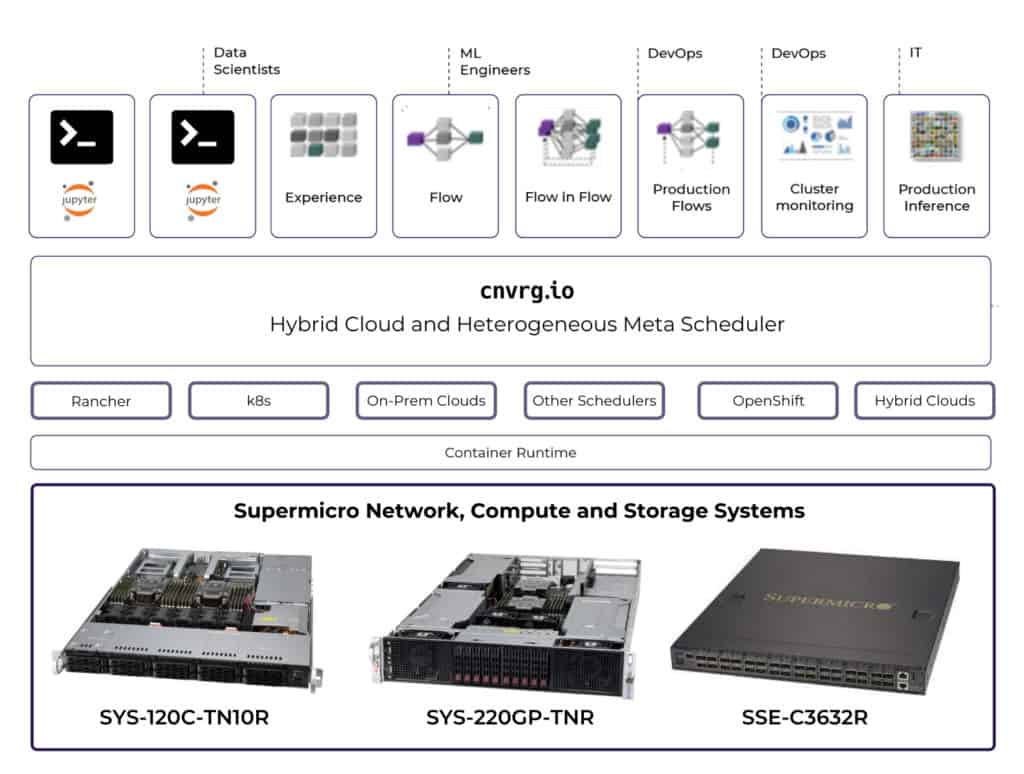
cnvrg.io bundled with Supermicro AI purpose-built servers creates a managed, coordinated, and easy to consume ML infrastructure out of the box. cnvrg.io running on Supermicro servers delivers data scientists and AI practitioners one unified control plane to build, deploy and manage machine learning workloads. With cnvrg.io, data scientists can bring high impact models to production faster and monitor models on top of the Supermicro AI purpose-built solutions.
cnvrg.io and Supermicro End to End AI Solution
Launch Any ML or DL Framework in One-Click
Accelerated workloads, with the ability to launch any ML or DL framework in one click with direct integration to optimized containers from both Intel and NVIDIA, optimized to increase performance of Supermicro servers featuring 3rd Gen Intel Xeon Processors and NVIDIA GPUs for AI workloads.
Accelerate Time to Value with Frictionless MLOps Workflows
The cnvrg.io platform, running on Supermicro AI-ready servers, provides data scientists with accelerated project execution from research, to training, to production. cnvrg.io enables enterprises to manage and scale ML in any environment quickly. Data scientists can run ML pipelines on diverse workloads to achieve maximum performance and accelerate time to production.
Increase Data Science Productivity
Data scientists can easily manage, experiment, track, version, and deploy models in one click in one unified solution. It’s container-based framework is designed to be agnostic, portable, and solves key MLOps challenges to help data scientists deliver more models to production fast.
Maximize Server Utilization with AI Workload Visibility
Improve visibility of your AI workloads in real time. The MLOps Dashboard allows granular visibility so you can maximize Supermicro server utilization. cnvrg.io MLOps helps streamline AI application delivery, so data science teams and IT can more effectively manage users, workloads, models, datasets, experiments, and more, while speeding continuous application delivery.