
In this webinar, data science expert and CEO of cnvrg.io Yochay Ettun discusses continual learning in production. This webinar examines continual learning, and will help you apply continual learning into your production models using tools like Tensorflow, Kubernetes, and cnvrg.io. This webinar for professional data scientists will go over how to monitor models when in production, and how to set up automatically adaptive machine learning.
Key webinar takeaways:
In this webinar, data science expert and CEO of cnvrg.io Yochay Ettun discusses continual learning in production. This webinar examines continual learning, and will help you apply continual learning into your production models using tools like Tensorflow, Kubernetes, and cnvrg.io. This webinar for professional data scientists will go over how to monitor models when in production, and how to set up automatically adaptive machine learning.
Key webinar takeaways:
Maya:
I’m going to introduce our speaker today, Yochay Ettun. He is the CEO and co-founder of cnvrg.io, and he’s also data science expert. So, I’ll let him take it from here.
Yochay Ettun:
Hello everyone. Thank you, Maya, for everything. So, it’s great to finally do this. This is our first webinar, actually, and going to be one of many. So, I’ll start with a quick introduction about myself and the company, and cnvrg.
I’m a data scientist myself, and also a software developer. We started as a group of data scientists doing consulting to other companies, especially in the field of NLP and speech recognition, and stuff like that. During that time we started, we need some sort of platform to help us manage our models, and we also saw that we waste a lot of our time on stuff that doesn’t really relate to data science like DevOps and IT, and stuff like that.
So, we built cnvrg from an internal product that we used, it turned into a startup, a business, and we’re now serving customers from all over the world, to help them manage, build, and automate machine learning. Besides that, our goal is to also connect science, data scientists with engineering, with DevOps, with IT, and to provide one platform to help you manage and operate machine learning.
So, today on the agenda, we’ll do a quick introduction about continual learning, and also, why do we need continual learning, why is this a concept today, something that you probably heard of and even thinking about starting to implement. So, we’ll also walk through a real machine learning pipeline with continual learning. We’re going to cover AutoML inside this, deployment and also monitoring. After that, we’ll show a live demo and an example of how to build your own machine learning pipeline using the MNIST example.
Okay, so, what is continual learning? With machine learning, basically, the goal is to deploy models through production environment. With continual learning, we see that we want to use the data that is coming in, in the production environment, and retrain the model based on that, based on the activity in the production environment. So, think of it as Netflix, for example, built a recommender system that recommends you as a user and what kind of TV Show, what’s the next best TV Show to recommend so you can watch it.
Now, that kind of model in production is something that needs to be retrained periodically because there are new movies, there’s new taste, there are new trends in the market. So, continual learning, the goal is to use data that is coming in, in production, and use it to retrain the model, so you can really gain high accuracy, high performing models and do that automatically.
Why do we need continual learning? The answer is pretty simple, and it’s because data is changing. Now, data is changing, could be because of trends, could be because of different actions made by the users, but the fact is that data is really changing, and we’ll give you some examples. So, Amazon best sellers from the year of 2000, the Harry Potter book, and today, it’s completely different. So, they would have to retrain the model and recommend new books to their customers.
A bit more updated example is the bitcoin price before the huge drop. In 2017, the bitcoin was 19K, about a month and a half later, it was 6K. Also, the English language has evolved a lot over the past years. For the NLP data scientist out there, you’d probably know how you need to interact with slang and all language. For comparison here, we have a Shakespeare quote with the Hotline Bling by Drake. And also, other stuff that changes is, for example, TensorFlow was the best deep learning framework in 2018. Today, everyone is talking about PyTorch, and I don’t know what’s going to be next years. And also, top Google searches, 2017 comparing to 2018. So, not a lot of change there but maybe next year.
All right, so, now that we covered what continual learning is and what the purpose of it is, let’s use MNIST, which is the most popular example of deep learning. We’ll use MNIST as an example of how you train, deploy and automate the process of machine learning in production. MNIST is an OCR application that, the goal is to identify numbers from handwritten text. We’ll use MNIST as a use case but think of it like, for example, we have a platform, we want to recognize handwritten digits, and since our user base in the platform is growing, we want to recognize more handwritten styles and different digits written by different users.
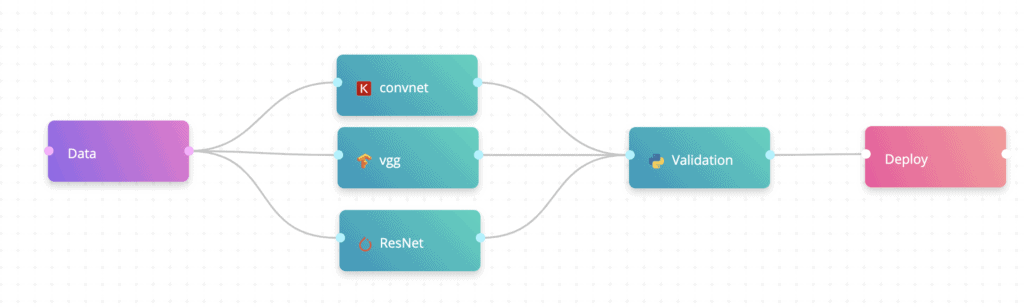
So, we want an ML model that whenever there is a new user joining the platform, we’ll retrain the model, so, we’ll gain really high performing accuracy and maintain great models. All right, so, the MNIST machine learning pipeline. We’ll start with how a pipeline looks in the production environment. So, first, we have the data, of course, data of images of handwritten text. Then, we do some sort of validation. It could be some test, some benchmarks internally like, is this data high quality or not? It could be, also, pre-processing that we operate.
We’ll also talk about AutoML in continual learning and why AutoML in continual learning is important. But think of it like this is the training step in the machine learning pipeline. After training, we’ll do some model validations to make sure that, let’s say we trained about 20 different models, we want to test them, make sure all of them are working well, and pick the best one, and deploy it to the production environment. Now, this is a classic machine learning pipeline but here, we’re adding also the monitoring and basically connecting the loop back to data.
So, predictions that are being collected in the model deployment area will be monitored, each prediction will be monitored. Also, after it will be monitored, we will clean the data and label it if required. For example, for our MNIST case, we’ll obviously need to have some human label the data, but for recommender systems and for forecasting, we’ll just be able to close the loop without the human label.
After labeling and cleaning the data, we’ll move it back to the data that is ready for the machine learning process. And now, we have a closed loop. This is machine learning. In this presentation, we’re going to cover those three components, AutoML and its importance in the machine learning pipeline, in continual learning. Then, we’ll talk about model deployment and how you deploy new models to the same environment without hurting your users experience and still maintaining high accuracy.
And then, we’ll talk about monitoring, how you can monitor your models in the production environment to make sure that if something bad is happening to your model or if the data that is being sent to your model is corrupted, you’ll be alerted. Because with continual learning, we’re guessing that every data scientist is going to manage several machine learning pipelines, not just one. Besides the fact that it’s going to be automated, the entire process, we still want to provide the data scientist with 100% control. Not only data scientist, also the data engineers, and the DevOps, so they will have 100% control on the entire machine learning pipeline, ready from research to production.
We’ll start with AutoML. So, why do we need AutoML in our continual learning pipeline? Simply because data is changing and data is affecting models. Now, I could just retrain the same algorithm with the same parameters, and doing it on a simple level, but because we still want to gain really high accuracy, we’re going to use AutoML. Now, AutoML doesn’t have to be really complicated meta-learning and stuff like that. You can really just use hyperparameter optimization, open-source algorithms and frameworks. As part of your research, when you start working on your machine learning pipeline, you’ll have to select your algorithm space.
For example, we’re doing a computer vision problem, so, we’re going to use transferring as our training algorithm. And with transferring, you have a lot of retrain models that you can use to retrain only the last layer of the network, and then have your model deployed. So, in our case, we’re going to select our algorithm space to be VGG, Inception, ResNet and a few others. Those are really popular prebuilt machine learning, deep learning networks.
For each algorithm, we also have to specify its range of parameters. Now, this could turn into a really big computational problem but we’ll be using automated DevOps to train the models. So, we don’t expect any problem with that but this is the data science part. You’ll have to really research what kind of algorithm is useful to your machine learning problem, and also, what kind of parameters.
With our problem, I’m going to use this code example, which is basically like an idea of how AutoML for computer vision should look like when using transferred learning. So, we’re going to use Keras with TensorFlow as back-end, and we’re going to use those networks.
With non computer vision problems, you also need to select the algorithm. What we see from our customers and also from the companies we’re working with is that XGBoost always wins, so, simply start with that. Select their parameters of XGBoost and just train the models. Okay, so, in the first step, we’re going to train a lot of models. As you saw here, I have three networks that I’m going to test. For each of them, I have about 10, 20 parameters also, that we are going to test. This means that it’s going to run 60 experiments. When, every time I want to train the model, it’s going to run 60 different experiments.
Now, it’s really crucial for me to track everything, not only the models in production. This is the most important thing, as a data scientist, as a data engineer, I have to know, always, model is not running in production. There are several ways to track models and experiments. Also, in cnvrg, we have this kind of feature but this is critical. If you put your machine learning on autopilot, and this is our goal, you have to make sure that everything is tracked and managed. Now, you need to track what kind of algorithm you were using, what the hyperparameters are, what kind of compute you were using, what’s the memory consumption, metrics, accuracy, all that.
Now, besides tracking the models in the production environment, we really recommend also to start building a database of all the models that you’ve built, even those that are not in production. Just track everything because the fact that I trained, let’s say, 60 different experiments today, this kind of data might be helpful for me next week when I’m trying to redeploy and retrain the model.
I can also do critical stuff like doing meta learning, try to understand what kind of algorithm are working well for my problem, for my use case, and then, minimize the number of experiments every time. Another critical thing about when doing AutoML, especially with deep learning, is that you have to automate your machine learning infrastructure. Now, we recommend using Kubernetes on top of all the cloud providers you want, but the fact that you’ll have a Kubernetes cluster up and running makes it really easy to deploy new experiments. So, the fact that I’m having, let’s say 60 experiments, using Kubernetes, I can just launch them very quickly and track them to make sure that all experiments are running well, and what’s the accuracy of every experiment.
Okay, once we train, let’s say 60 experiments, I chose the best one, I have my internal test. I chose the best one, the one that has the best accuracy, and I want to deploy that model now. Now, this is a bit different from normally deploying models. Usually, even a data scientist will be able to deploy a model but since this is going to be automated, we have to do it very carefully because you don’t want to deploy. … Just like you won’t deploy a software that has a bug to a production environment, you won’t deploy an ML model that was not trained successful. You have to run tests before deploying, during the deployment, and also after the deployment of the model, and you have to define your benchmark well. Benchmark would be accuracy test on previous passed data.
For example, in our case, so, we’re training a model to recognize digits, so, we’ll train it on the new data, but we can test it on old users. So, we can be sure that the new model is working well, even on old data. Other stuff we should keep in mind is also the performance because in our case, you’re using different kinds of prebuilt algorithms. We want to make sure that if we use a different algorithm, that it won’t hurt the performance of the platform. So, you have to also keep in mind, testing the performance and the system health.
Now, in software development, usually, there’re a lot of different ways to deploy new software. We use the process of continuous integration and continuous deployment. For machine learning, we really recommend, Canary deployment. Basically, it’s a technique to introduce new software version in a way that effects only parts of the users, then gradually increase the number of users based on the tests. So, you set up the test, you set up the benchmarks, and then the platform, using this technique, is going to gradually deploy the model to larger subsets of users.
We have a link here to read more about it, and we’ll send it also after the webinar, highly recommended, and we’ll also go over it in the live example. All right, now, for model deployments, those who are with the data engineering background, you probably know Kubernetes. We’ll also cover it in the live example but we recommend using Kubernetes alongside with Istio, so you could do an A/B test, you can make sure that your model is deployed well. And we also have a guide on our blog, written by our architect, so, you can go over it, and we’ll send the link at the end of the webinar.
Okay, almost the last step in the pipeline is monitoring. So, once you deploy the new model to the production environment, the goal is to provide the data scientist with the control and the transparency they need so they can monitor the machine learning model, not only data scientists but also data engineers. Also, for the ability to automatically deploy new versions of the model, you have to monitor the input data, so, we’ll also cover this in the live example but there are great tools in Kubernetes, Prometheus or alongside with AlertManager where you can monitor all the input data.
In our machine learning use case, we’re going to search for unexpected values first. So, for example, I deployed an MNIST model, I expect to get handwritten digits. In case I’m receiving, suddenly, a completely different thing like, I don’t know, a giraffe or something, then I would want to be alerted because it doesn’t mean my model is wrong – but it means that my model is not being used well. And so, it can produce bad predictions and that’s going to be bad for the users, and also bad for the business.
Next is measuring correlation of production data to train data. Now, my model is basically deployed with the knowledge it gained from the training data. So, my goal is to make sure that if there is a value that I’m expecting it to be … it’s like a digit but it’s not correlated to the trained data, it also means that this is bad data. But it means that in a way, I need to retrain my model. So, I would want to get alerted on that.
Now, when building my monitoring system of my machine learning pipeline, I have to keep it open. Very easily, you have new ideas, new tests, new rules that you want to add to the platform, to the model, so, you have to make it really accessible, also to the data engineers but also to the data scientists because they can think of a new parameter they will want to inspect, especially for input data.
Besides input data, I would also want to monitor my predictions, so, I would want to see that for each prediction, my model confidence is high, there is no model bias, and I can think of a lot of other examples but this is real data science, and this means that my data engineer that I’ll be working with on this project will be in the loop, and can keep it open, so I can add new functions and new rules. Now, like I said before, we recommend using Kubernetes, Prometheus, and also AlertManager to solve this kind of problem.
The last thing is about triggering the retraining. So, basically, here, it’s closing the loop. So, I have the data, I’m running the training, I’m collecting the predictions, I’m monitoring the predictions, I’m cleaning the data but here, I want to decide when I would retrain my model. So, there are several ways to do that. We have customers that retrain their model periodically. For example, for recommender systems or ads, or stuff like that, you would want to retrain the model, we have teams that retrain the model every 30 minutes, so, they have a perm job that is retraining the model.
You would also consider retraining the model only on new data that is coming in. So, in our case for example, we have a user base that’s uploading images of handwritten digits, so, I would want to retrigger training whenever there is X amount of new users because this will help me to keep my model in very high accuracy. Other ways is to track and monitor model decay and model bias, low confidence and any kind of other alert in production environment.
Now, this is also something, before you deploy the continual learning pipeline, you have to consider those three reasons. The most important thing is that if you trigger the machine learning pipeline automatically, then you would have to track and validate the trigger because not knowing that your model has been retrained because of a specific reason is really bad, and knowing that would help to understand and debug the model in the production environment. All right, we’ll go through, now, a live example but before that, do you have any questions?
Maya:
Is there an example of production data vs. training data correlation?
An example on production data versus training data correlation, first of all, it’s a great question. You would see it a lot in recommender systems. So, you built a recommendation system that recommends you the best next movie, and after a while, especially when you have a lot users and a lot of traffic, and a lot of clicks and stuff like that allow you build the model, after a while, your training data won’t be relevant. So, you’ll be able to use some algorithm to test if the input data is correlated to the data that your model trained on, and if it’s not correlated, then you might want to retrain the model.
So, we’ll now use cnvrg, our cool machine learning platform to show you how you can build a machine learning pipeline that can continuously train from new data. So, like we talked about in the entire presentation, we’re going to use MNIST as an example of how you build this kind of pipeline.
So, first, we’re going to go over to the code, so, we have the MNIST algorithm here. It’s simply using a ConvNet, really from the Keras example, and we’ll also be able to debug this code using Jupyter Notebook, but we’re going to skip that. Hold on a sec.
Okay. So, flows in cnvrg, it’s basically the ability to build production ready machine learning pipeline with just drag and drop. So, we’re going to build our training pipeline. First of all, we’re going to choose the data set, the MNIST data set. It’s simply a bunch of images of handwritten digits. Now, here, I’m going to use one of the algorithms in our AI registry. Now, we saw that we already wrote the code, so, we’re simply going to use ConvNet. This is the code that we saw before. Here, I can see the documentation of this algorithm and the different parameter.
Remember, we talked about AutoML, so, here, we have comma-separated values, which means that cnvrg will test all the possible permutations and make sure that I have the best model in the production environment. Besides that, we’re going to use VGG as well, this is a prebuilt network built by a team, I think in Oxford, and we’re going to connect the dots. Let’s see if I have another … Let me also use my own PyTorch.
Okay, after I design the first part of the pipeline, this is going to train my models using Open source, Keras, TensorFlow and PyTorch. And then, I’m going to use validation, so, I built my own validation script that basically takes the models that I built and runs some tests on top of them. Those tests are related to the accuracy, first of all, also to the size of the network like the complexity of the computation, and also to the performance like how fast it is. In production, to run some tests just like software tests before deployment, this is going to be our test for our model.
And then, I’m going to deploy the model to a Kubernetes cluster using this deployment button. Now, once I click run, cnvrg will basically calculate how many experiments it’s going to run. In this case, I’m running only 18 experiments, so, it’s going to do AutoML on 18 experiments. Now, in the next tab, I have all the experiments that it ran, so, I can see exactly what has been happening in my model, the VGG, the ConvNet. I can also see the different metrics, so, remember, we said we want to track all the metrics, all the hyperparameters. Every experiment gets this dashboard that I can track live. I can see resource usage, I can see metadata, I can see hyperparameters and metrics, I can see loss. I can really track everything.
Like I said before, it’s not only useful to know what kind of model is being deployed in production, it’s also useful to know afterwards. Me, as a data scientist, my research job is not over, even when my model is in production. So, next time I’m going to research this problem, I want to see if I can maybe improve the algorithm, improve that parameter, I can safely see all the experiments and I can click compare, so I can make sure that all the models that I built are tracked, and I can choose the best one, and then deploy that one to production.
Now, last part, like we talked about, is basically the deployment and the monitoring of the platform, of the model. So, I simply click deploy. Now, in the back-end, at cnvrg, we’re using Kubernetes and we’re using Kubernetes alongside with Istio and Prometheus, and the AlertManager. So, every model that is being deployed in one click, like you simply choose a file and function, just like function as a service, all the models that are being deployed are monitored. So, the data scientist can see exactly what the status of the predictions are. You can also get this URL that you can share with your colleagues, and you can also see all the input and all the output of the models. So, you can download this as a CSV and retrain the model on new data.
Now, the cool thing about this is that you also have the continual learning tab. Now, the goal of continual learning in our case is, first of all, to provide transparency and control to the data scientist. So, they can add rules to monitor input data, so you can see that if you get unexpected values, for example, with some sort of sensitivity, then the data scientist will get an email. Besides that, you can also monitor the prediction themselves, so, we can see that if the model confidence is below 0.5, then retrain the model using the machine learning pipeline that we built earlier. This is really just closing the loop, providing an end to end solution for the continual learning pipeline. The data scientist will be alerted when there is bad input, when there is data that is not correlated to the trainer test data.
I can also use my own custom validations, I can add other rules and make it really easy for my data scientist and data engineers to manage the machine learning pipeline. Now, we talked about also other ways of retraining the model. So, we can do the same with this, you can trigger a flow on dataset updates. So, whenever there is a new version of this data set, it will be automatically rerun through the training pipeline. You can also do the same with scheduling, just retrain this model once a week, whenever there is a specific date and time.
Okay, we have a question by Irene. Is cnvrg able to do hyperparameter search? Yes, in the flows, and also, you can use Jupyter Notebooks and also the cnvrg CLI. You can basically specify the hyperparameter space of each parameter, and once you click run, cnvrg will automatically test all the different experiments, all the different hyperparameter, and report all the results, track all the results in a way that you can compare the results and choose the best model. You can also do that automatically.
Okay, another question by Irene. How is low medium, high sensitivity defined? So, in the model deployment section, you can specify rules. Now, for example, I want to test that for each input data, if you get unexpected values with low sensitivity, then I will get an email alert. So, in this case, no means that, basically, cnvrg samples the model once every specific timeframe. Could be once an hour, once a minute. So, if this kind of error happens five times an hour, then it will not send an email, but if it’s happening 20 times in an hour, it will send me an email. Now, you can configure all those sensitivities in the organization setting, so, everything is configurable.
For example, if I get unexpected values with high sensitivity, so, it’s enough that I’ll receive it once and then I’ll get an email. Now, we made this because, for example, for model decay, you might see one instance that the model confidence be below 0.5. And, you wouldn’t want to retrain the model based on one time. So, this is exactly why we made that possible.
We’ll do a quick summary and then I’ll give it back to Maya to conclude. So, continual learning is the future of your machine learning models, it really is. We see this becoming more popular with our customers as well because you would always want to keep your models in high accuracy, and a lot of the machine learning problems you will always get new data. So, continual learning is basically going to be a really big part in your work, and we really recommend you to do it because it is doable, and it is worth the investment. Building an autonomous machine learning pipeline is, first of all, really cool but also, it really provides results for the business, for your customers, for your users, for everyone in the organization.
Once you do it, we do recommend adding a test. Add a test in every stage. Building an automated machine learning pipeline that is in production is great but it is very important that you add a test for every stage if it’s for monitoring the data, if it’s for testing the AutoML pipeline, for testing the model after and during deployment.
Now, a lot of teams will want to build it on their own and that’s great. We listed a bunch of tools that you can use to get this pipeline up and running but what is important is that this continual learning, your machine learning pipeline are going to be maintained by two types of users. We see this a lot at cnvrg. So, one type of user is the data scientist, the researcher, the PhDs, the algorithm people. And the others is the engineering, the DevOps, the data engineers, those who can really put stuff in production.
So, when you’re building this kind of machine learning pipeline, you have to consider both users. Make it easy for a data scientist to research and track the performance of the models, but also make it really production ready and with all the data engineering tools.
We also have some links that we’ll send after this webinar is over. but the main paper I would recommend reading is Continual Learning in Practice. It’s written by a group of researchers at Amazon. It’s a really good paper, very practical, and gives you a lot of ideas of how you can implement this kind of pipeline on your own.
Next up in our webinar, stuff that we didn’t mention in this webinar but definitely worth reading about is active learning, how you can automatically take the data that is in production and retrain the model without humans, and also how you integrate humans in the loop. How you integrate labeling, tagging, and validating the data manually.
Maya:
Thank you all so much for coming. We hope you learned a lot. We’re going to be sending out to all of you a recording and the slides of this webinar so you can share it with your co-workers, your friends, and you can have it to look at. There are a few questions that weren’t answered today but we will be happy to answer them offline because we’re running out of time here.
So, if you have any questions, please respond to the email that we send to everybody with the recording, and one of our machine learning specialists will get back to you.
Besides that, we hope you come to our next webinar, and we’re happy to also get any feedback in our email, so, look out for that. Thank you so much for coming.
Yochay Ettun:
Thank you very much everyone.