
Computer vision is rapidly enhancing how technology reacts with the world around us. Whether it’s autonomous vehicles, handwritten text recognition, face recognition, or detecting disease from x rays, computer vision is greatly improving all industries. Teamed up with the capabilities of AutoML, data science teams can accelerate model development by automating the end-to-end process. AutoML makes machine learning workflows simpler, allowing data scientists to build more complex models.
In this webinar, data science expert Yochay Ettun will present a step-by-step use case so you can build your own AutoML computer vision pipelines. Yochay will go through the essentials for research, deployment and training using Keras, PyTorch and TensorFlow. He’ll provide an overview of infrastructure and MLOps using Docker, Kubernetes and elastic cloud services. This webinar will enable you to build your own custom AutoML computer vision pipeline and help your business apply machine learning on more use-cases, problems and projects. The aim of this webinar is to democratize machine learning so software developers, engineers, and data scientists can feel confident building a computer vision pipeline.
Key webinar takeaways:
Computer vision is rapidly enhancing how technology reacts with the world around us. Whether it’s autonomous vehicles, handwritten text recognition, face recognition, or detecting disease from x rays, computer vision is greatly improving all industries. Teamed up with the capabilities of AutoML, data science teams can accelerate model development by automating the end-to-end process. AutoML makes machine learning workflows simpler, allowing data scientists to build more complex models.
In this webinar, data science expert Yochay Ettun will present a step-by-step use case so you can build your own AutoML computer vision pipelines. Yochay will go through the essentials for research, deployment and training using Keras, PyTorch and TensorFlow. He’ll provide an overview of infrastructure and MLOps using Docker, Kubernetes and elastic cloud services. This webinar will enable you to build your own custom AutoML computer vision pipeline and help your business apply machine learning on more use-cases, problems and projects. The aim of this webinar is to democratize machine learning so software developers, engineers, and data scientists can feel confident building a computer vision pipeline.
Key webinar takeaways:
Maya:
Hi everyone, thank you for coming. My name is Maya Perry. I’m the marketing manager at cnvrg.io and this is Yochay Ettun who will be presenting today. If you have any questions throughout the webinar please feel free to write in the Q&A section and we’ll have certain times where we’ll go over the questions and answer what we can and of course just feel free throughout the entire webinar to just post them and we’ll get to them later on. This is the CEO. I’m going to let him take it from here.
Yochay Ettun:
Hi everyone. Thank you very much for joining. All right, so our webinar today basically is about AutoML for computer vision. You will mostly hear AutoML more in the field of analytics and predictive analytics and stuff like that. Here we’re going to use AutoML for building computer vision models. It might sound a bit challenging but actually it’s pretty easy and we’re going to use a bunch of open source framework for that if it’s TensorFlow, Keras and Kubernetes as a compute engine.
All right. So myself, I’m one of the founders of cnvrg. Cnvrg is a platform that was built by data scientists for data scientists. Our role is to help teams to manage, build and automate machine learning from research to production. We provide a model management platform where you can really track the entire workflow of machine learning and we also bridge science to engineering in one place to build and deploy machine learning.
We’re supporting a lot of companies in different fields. One of the fields is AutoML and computer vision. The agenda for today, we’ll start with an introduction answering what AutoML exactly is? and why we need AutoML for computer vision? In a recent survey of Kaggle they said that computer image data is only about 20% of the machine learning problems that people solve around the world.
We’re going to answer the question, why do we need AutoML for a computer vision problems? We’ll discuss the different approaches of doing AutoML and we’ll do some hands on building of a machine learning pipeline that can really get any kind of data, produce a model using hyper parameter optimization and tuning and a bunch of other techniques and we’ll deploy the model to production. All right, so what is AutoML? Automated machine learning is basically the process of taking the entire machine learning workflow and automating it.
You can load any kind of data. You do the pre-processing, you do the feature engineering, you do the training, the testing and the validation, and then you deploy to production completely in an automated way. It can support any kind of data and any kind of machine learning problem. Usually we’re talking about classification problems that you need to classify whether this customer is about to churn or whether this text has some bad sentiment or if this image has a cat in it.
We’re going to discuss AutoML in the computer vision world. Why do we need computer vision? Why do we need AutoML for computer vision? There are a lot of different applications in computer vision and this field of computer vision is really growing rapidly. The amount of use cases we see is really rapidly growing. If it’s health, if it’s nature, you can even classify whales which was a Kaggle challenge. You can identify agricultural stuff and nature to make the world better.
You can also look at the manufacturing field and you can see that computer vision is used a lot, especially with the robotics field you want to identify some components in the manufacturing process. You want to make sure it’s valid and you want to move it in the next stage. Computer vision is also used for emotion classification. You want to identify whether the person is happy or sad or nervous or angry. It helps to really personalize the experience for users and for the people who are your customers.
And of course you can use AutoML for computer vision to solve world problems like identify a hot dog or not a hot dog automatically. Why do we need AutoML for computer vision? Like we said, the demand for image classification solutions is really growing. We see this with our customers. You can build not only autonomous driving applications, but also a lot of applications in the manufacturing space and in the business space. If it’s fashion, e-commerce, nature, agriculture, security, and a lot more.
Thanks to deep-learning and advanced research it’s becoming easier to build those models. We’re going to talk about two different approaches for computer vision AutoML. The first one is called transfer learning and this technique is basically taking a model that was prebuilt using a very large dataset and apply it to your own domain. For example, you’re using an open source algorithm that can classify animals. You can use that in the same space. Second is about neural network architecture search.
You can basically take deep learning networks and search which one is the best fit to your model. Now, we’re going to talk about those two topics in depth over the next 10 minutes. But before that we’ll stop for some questions. We’ll try to make this a bit more interactive session. If anyone has any questions during the presentation just shoot a message. Transfer learning. We’re going to talk about transfer learning. Transfer learning is basically taking a deep learning network that was built on a specific data, usually a lot of data.
You can see a lot of famous deep learning models used in this case and you are going to take the previous models and retrain them on your own small dataset. This is why transfer learning is really useful when you don’t have a lot of data because it has already learned from a lot of data so you can use that for your own models. One of the things about transfer learning is that you can see a list of a lot of machine learning models. They were trained with a lot of different data sets and it is very easy to use.
One of the things about Keras that really simplifies deep learning development is that it’s only two lines of code and you’re good to go. We’re now going to do a real example. This is a transfer learning code example. We’re going to use transfer learning. Like we said, this is an example that you can use a lot of prebuilt models and you can already use them to build your own pipeline. We’re going to use cnvrg to try to simulate how you can build an AutoML pipeline very easily.
But the code that we’re going to use is open source and it’s code that we wrote and we’ll make it public after the webinar is over so you can use that to build your own machine learning pipeline. Let me launch a workspace. We’re going to do that in an interactive way or going to use Jupyter notebooks. It’s a very common tool to build models and as you can see here this is the Keras code. You have the different parameters right here. Those are really classic deep-learning parameters. You have epoch, you have batch size, you have hidden nodes, dropout, learning rate and a lot of other very common use cases.
Now, with transfer learning because we said in this slide that you have a lot of example, a lot of prebuilt models that you can use. We’re going to build a script in a way that it’s agnostic to the type of the model. With Keras you can basically import any kind of the open source models very quickly with just one line and then you can train the models. We’re going to build one script to support any kind of base model. One of the conditions here is basically if this base model is ResNet then we’re going to load the ResNet model.
One of the things when choosing, because we have a lot of different prebuilt models you’re going to need to do some research to make sure that if you are training a model that really is all about indoor advertising, you need to make sure that the prebuilt model that you’re using has learned similar stuff in their own data set. Now, the thing is that a lot of the time the stuff neural networks learn on – especially in large networks like ResNet – is good enough to solve almost any kind of problem.
You want one to experiment with different networks and you’ll be surprised it’s going to get good results. After we chose the deep learning based model we’re going to basically load the data. Of course in the AutoML pipeline we want to be able to support any kind of data loading. Any kind of data, any kind of augmentation and stuff like that. We’re going to build a data generator. This is also using the Keras example and a training generator. As you can see here I’m just sending the target size of the generator.
And here basically this is the main function and it’s building the model. It takes the last layer of the model that we picked and it retrains it with my new data. This is really the core of transfer learning. It will take the neural network that you have created from the base model and it will just take the last layer and retrain it with your own data. It does capture all the data that you have before from the model that was prebuilt and then you can use it to be like a base for your own model.
This is a transfer learning. It’s really simple to use. I think it’s the most common application for computer vision. You have a lot of open source prebuilt models but we saw teams that already have a lot of data so they build their own transfer learning models and the results are really good. Next is something that is a bit more complicated and it’s called neural architecture search and neural architecture search is an algorithm. Basically it searches the best neural network architecture. It does not take a prebuilt model.
It basically builds the network on its own. This became really popular mainly thanks to Google that has done a lot of research in that field, it’s the Google brain. The goal here is for any kind of data you’ll get a custom neural network architecture. In this case, an RNN network, which is called the controller, is trained to build your neural network architecture. It samples a candidate architecture, it trains it, it tests it, and then it uses the performance as a guiding signal to find other architecture.
As you can see here we have the controller which is the RNN network. It does not relate to your output model. This is basically a model that can learn which architecture to pick, then it samples in architecture and then it trains that child architecture to git and receives the accuracy. Based on the accuracy that it got it goes back to the RNN, which is based on low short term memory architecture and rebuilds the pipeline until it gets the best results. Now, the optimization method is here because it really needs to understand what kind of neural network you should search for.
We’re using optimization called reinforcement learning or Bayesian optimization, evolutionary search and a few more. Here we have the paper that presented this research. We’ll also share this after the webinar. Now, one of the things people say about neural architecture search is that it’s computationally intensive. When presented one of the first papers about this mentioned that it took 450GPUs for four days to train a single model. It does make sense because think that each of the times you need to retrain the model.
You’re training hundreds of models just to pick the best architecture. Even though it has optimizations and stuff like that you’ll still have to retrain the model a lot. Now, the thing here is that a new paper also by the team at Google Brain presented a new algorithm and efficient neural network architecture search via parameter sharing. They basically share parameters during the search, it makes the process a lot more efficient. Now, a lot of the other things that people say is that this is really hard to implement. It’s very hard to use.
It’s hard to understand and it’s hard to make it in real world applications. But there is an open source library called Auto-Keras which is really great. It’s basically implementing an efficient neural network architecture search with real world examples. We’ll also share our link to how to use it and it’s great to use it that way. Now we’re going to basically build our own AutoML pipeline. What we’re thinking about now, how we can build this pipeline. Our goal is basically to have this machine learning workflow running in our company in production environment.
It’s not a research project. It’s something that we need to provide to our customers whether it’s internal teams in their organization or external customers which is important to have something that is really high performance, and reproducible. One of the things about machine AutoML is that a lot of the time you lose track of what’s working and what’s not. It’s very important to have reproducible machine learning in that process. We also want to make it efficient because we don’t have 450GPUs for every model that we build.
We want to make it really simple, efficient, and fast and we also want it to be end-to-end really from training to production and also back to training if required. We’re going to use Keras on TensorFlow, we’re going to use transfer learning for that and we’re going to use Kubernetes as the backend pipeline. Now, we will use cnvrg to make everything play but this obviously can be used with your own Kubernetes cluster and we’ll share the code samples when the webinar is over. Our pipeline is pretty straight forward.
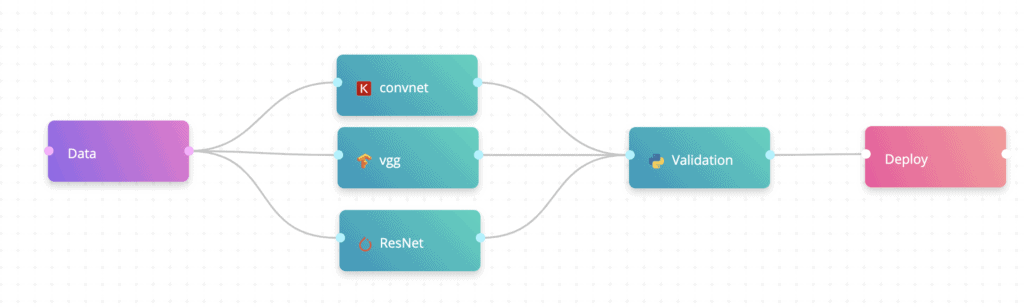
We’ll have data, we’ll have training, we’ll have validation, and we’ll have deployment. Our goal is to support any kind of image data. We’re expecting any data that we support to be images and also to be with labels so we’ll know exactly what the truth label of each object is. We’re going to transfer learning with famous neural networks. We’re going to select a bunch here. Here it’s ConvNet, to VGG and ResNet. This is PyTorch, this is TensorFlow and this is Keras. And we’re also going to test everything.
AutoML can be really tricky. It can very easily over-fit and you have to make sure that you’re building the models right and finally deploying the model as a REST API endpoint. Before the demo, any questions? All right, so we see one question.
“If a model recognizes apples, potatoes and cabbages I want to add mango. I’ll need to train from scratch or I use transfer learning?”
The answer is yes. In order to add a label and to have your model support the new one, you’ll either need to retrain the pipeline with the new label or use the extracted model from your previous pipeline and use it as a transfer learning.
We’re now back to the cnvrg platform. We are going to see how we can basically build a machine learning AutoML pipeline from here. We’ll quickly go over the code. As you can see, this is the backend of the pipeline that we’re using. This is the core basically loading hyper parameters for the algorithms and the most important one is the base model. This basically chooses which model I am going to use to do the transfer learning. I can do a bunch to really make sure that I’m testing all different variations and I can just choose one to have my results fast.
Then I’m going to load the data generator and eventually I’m going to fine tune my model. Like we said earlier, this is the core of the transfer learning application. We’re going to load the base model, cut the last layers and retrain them with my new data. It does not require a lot of new data. I can just use a thousand images as long as they’re labeled of course and then I’m going to save my model weights and then we’ll deploy those models to production.
We have another question here. “What’s the difference between AutoML and GoogleML Engine now called AI Platform? For which scenario do we use each tool?”
The answer is, there is AutoML that is loading data and automatically producing models. We found 3D coding. This is what we’re going to show here and the GoogleML Engine is basically for building the model on your own.
This is our machine learning pipeline. It’s pretty straightforward and simple. First we have data preparation. We’re going to load the data and then we’re going to use transfer learning. This is the script that also will be shared. We’ll skip that. This is the script that we’re going to run. We’ll also share that.
These are the different types of learning rates that we’re going to use. We have here also batch size and these are the different base models that we were using. Now, here you see we have different heights and width for the data set that we’re getting from prep data and at cnvrg you can basically refer to previous components so this is also easy. Now, in AutoML you would almost every time – like in transfer learning or neural architecture search – you would want to automate your DevOps.
You would want to run a lot of experiments in parallel making it very efficient and also in transfer learning. If you think that for every deep learning network you have a lot of hyper parameters so you would obviously want to optimize it for the best use. In cnvrg similar to other open source you can select a range for your hyper parameters. In learning rate I can have common separate values and then when I run this pattern cnvrg will automatically test all the permutations and optimize my model automatically.
You can also do the same for epochs and we also do the same for different transfer learning models. We could just pick the best model to fit the data but we said we really want to make sure that our data scientists don’t waste time and stuff like that so we’re just going to try everything. Also, one of the cool things here is that let’s say I want to use a specific model, for example ResNet, so I can connect the dots and then those two models will be running in parallel. Now, once I click run this will execute 13 experiments in a single click and then I can see exactly what’s going on in every experiment.
We have another question. “How will this solution work for image classification which looks almost similar? For example, will this solution be able to classify different types of screws or bolts which vary in size or length?” The answer is that basically because we’re using transfer learning, a lot of the features, the characteristics of each image are already learned by the base model. If you have a lot of data then you’d be able to either train your own deep learning architecture from scratch or you can put more weight to the last layer.
But this really is if you have a lot of data, but it is very much doable. Now we’ll go to one of the experiments. Here we have all the models in cnvrg. All the pipelines that are run are being automatically tracked. This is the command that we want to build that we ran. The test example has successfully finished now we’re in the transfer learning phase. Here are all the hyper parameters and metrics and you can see if the loss has converged. This is a good sign. This is less, but the accuracy converged to almost one.
Also the accuracy and the validation accuracy and also the loss converge to zero. This is a really good example and a model that really converged well. This was running on 10 epochs and here it’s created the model. We train 12 different models. Let’s see their status. Alright, so we just started, but we trained basically 10 different models. I’m going to use the models that I built before and here as you can see I can just select. I can compare the models and I can see all the models side by side.
I can really see what happened in every model and I can compare side by side the different metrics and the different types of parameters so I can make sure that the best model will be deployed. The last stage of a machine learning pipeline besides the fact that we now trained all the models we want, we can now use one of them and deploy it to production. Eventually our goal is to be able to have these pipelines that we want to serve the model as a REST HTTP endpoint because this is the most common protocol and can be very easily consumed by our customers and your users.
So you’ll be able to get like an HTTP URL that you can either integrate in your application, embed in your application or just share with your team. Next we’re going to go back to this pipeline. Before that we’re going to show you how the code for a deployment looks like. Because all of our models in the transfer learning application are built with Keras, we’re going to just load the model using the load model Keras code example and then we’re going to write a predict function. You are going to load the image, this predict function gets a file path and you’re going to load the image with a target size, with the pre-processing that you need.
I am going to switch it to an array, convert it to an array, and then reshape it to the same size of the model. And then you are going to predict the class of this image and then return the results. This is pretty straightforward. Also, will be shared as an example. And now in this pipeline we’re simply going to edit our machine learning pipeline and add another component. We will call this one deploy and we’re going to add the file that we just saw and the function. And then once I click run again it will automatically get the data.
It will train my model using high parameter tuning just like here and then it will take the best one, the one with the highest accuracy and deploy it as a server, as a web service. Here I have my model, shared as an API that can simply copy, I’m going to call this a URL. Just copy that. This URL expects a five. We’re going to send 5.png to this URL and I get the prediction. Now, the cool thing about this is that for every model you can see actually what’s the input and what’s the output so we can monitor our results.
We have a question about how you can make all the rounds parallel. Like we said, for cnvrg you can simply specify a range of parameters and once you click run cnvrg will automatically take the compute environment that you want, whether it’s a GPU or not a GPU and run it in parallel. This one produces 12 experiments. For each experiment cnvrg will scale up your AWS cluster. It will set up an instance, get the Docker environment, run the experiment and also report live how it progressed and then it will shut down the experiment when it’s over.
If you are not using cnvrg then we highly recommend to use Kubernetes. You can set up your own Kubernetes cluster on Google Cloud or on AWS and have auto scalability. It will be a bit more complicated but it can help you to reach the elasticity we see here, the fact that one click you can launch 30 experiments. We have a question. What metrics and results do you log in the deployment and do you have a dashboard for that? The answer is that we log basically everything from the machine learning health to just the input and output. We also log the system metrics. Let’s say I want to monitor the cluster, the CPU usage and the memory and everything. You also have Kibana already built in on the cluster that we help and then you can really visualize your logs. You can also set up alerts and update the model based on the different alerts.
We have another question. How do you track your machine running training. There are a few open source solutions to track your models. We provide in cnvrg one model management algorithm out-of-the-box. But I do want to emphasize that if you are building an AutoML pipeline it’s critical that you have model management for that. You have to track everything. You have to make every model reproducible. The fact that you can now rerun this model or export it and research it locally is critical because with AutoML you suddenly get 30 models in production to your users and you have to make sure you know exactly how each model is built.
We have another question. How do you feed back runtime inference results for retraining? There are several ways to do that. For every model in deployment you can attach a dataset in cnvrg and then cnvrg will automatically push new results to the dataset. And you can also of course download manually. You can export your data to a CSV and just work on it locally. We built this AutoML pipeline at the deployment again. This will deploy the best model that was trained.
We have this pipeline and it’s good to go but it’s not really user friendly and we want our customers to be able to use this not through this URL, through this API and use it completely in an independent way. We’re going to use a webhook. For every pipeline that was built in cnvrg it can be triggered from an external API. If I’m going to now call this URL, then cnvrg will automatically run this pipeline and we’ll create a new endpoint. This is really cool because it’s exactly the use case for the custom AutoML pipeline, as you can wrap this URL with your own user interface and you can have a dashboard where users can upload images and labels.
And then once they submit the data, it will automatically run this pipeline and create their own endpoint.This way you basically built your own custom AutoML pipeline that can give you really good results and it’s very efficient and fast so you can scale to build more computer vision solutions in your organization.
We’ll summarize. AutoML for computer vision is doable. It’s easy, it’s scalable and you can do that on your own. We’ll obviously share the code that we use, but you can very easily build your own AutoML computer vision. You can use other solutions like external solutions like Blackbox Solutions for AutoML but we really recommend that you build your own. It’s not hard. It’s not more than just one script to run and it will obviously provide you better results than using external resources and solutions and this is mainly because you know your data best. Your data is something that you are familiar with. You’re the domain expert and it will be very easy for you to set up this pipeline and you will probably get better results.
Now, we covered two approaches to do AutoML. One of them is transfer learning and the other one is neural network architecture research. In this hands on example we took the transfer learning approach but we do recommend looking into Auto-Keras. It’s a great tool. Also make sure to invest time in building the end-to-end pipeline. Focusing on training and testing is really what we like to do the most, seeing how our models converge and how we reach high accuracy.
But to really make AI democratized in your organization you have to wrap it as an end point and you’ll have to also work on the pre-processing and make sure that your machine learning pipeline is scalable and robust and can work with any kind of data. Last thing, and I think this is really the most important thing, is you have to track everything. You have to track your data, data versioning, you have to track your code.
If you change anything in your code it has to be tracked in a way that you can see exactly what were the changes, whether you’re using it and you have to track your experiments and models in production and also the predictions. You can use those predictions to learn. You can use those predictions to get alerts and you can basically learn a lot from everything.
We’ll now go to Q&A. The next session is how to set up your own Kubernetes cluster.
With Kubernetes you can build your own AutoML. We do have some questions. “By saying AutoML for computer vision is doable, is it going to be expensive to use it? How much Google Cloud credit or money do you typically have to pay for a small medium project for computer resources?” It can be really cheap and it really depends on how much data you have and what’s the complexity of your computational pipeline.
But if you choose one base model with a bunch of hyper grammar that you want to tune, it shouldn’t cost a lot. Transfer learning is pretty quick. It’s not like building a deep learning model from scratch. I can also share that. The backend for Google’s AutoML is basically transfer learning and with some neural architecture search. Second question is, “I’m using PyTorch for my work, is it supported and what about the costs?” Yes, cnvrg.io supports PyTorch. To learn about our pricing plans you can speak with an ML specialist or visit our pricing page or you can use our community ML platform, cnvrg.io CORE. In cnvrg you can use any kind of framework including PyTorch to build your own transfer learning application. It does not cost money to build your own pipeline.
We do have another question about the back end of everything. Again, mostly we touch the data science part, such as building the algorithm part of the AutoML pipeline but for the backend we recommend using Kubernetes. We really think this is going to dominate the world of machine learning and also big data analytics. If you are trying to set up your own Kubernetes and you’re having a hard time doing that we recommend you to sign up to our next webinar which will help you to set your Kubernetes cluster. Thank you very much.
Maya:
Thanks everyone for joining us and sticking it through till the end. I hope you learned a lot. I will be sending an email to everyone with all of the information. We’ll have the slides and a recording of this video so you can go through everything that you need to. Feel free in the email to message us back with any questions that you weren’t able to ask or if you watched it again and you had more questions, we are available and would love to talk with you. We love talking data science. Thank you all and we’ll see you next time hopefully.