


Machine learning development has come a long way. With the adoption of containers and Kubernetes, DevOps or Machine Learning (MLOps) engineers can optimize workloads with custom images that maximize performance of your compute. But, many data scientists require DevOps or MLOps engineers to build custom images, install and connect compute to run AI workloads which can cause workflow delays and bottlenecks. Building an ML pipeline can take hours or even days to configure and deploy.
Now an end-to-end machine learning platform available from cnvrg.io allows data scientists and developers to build and deploy AI models at scale and can launch containers optimized for oneAPI that can accelerate workflows.
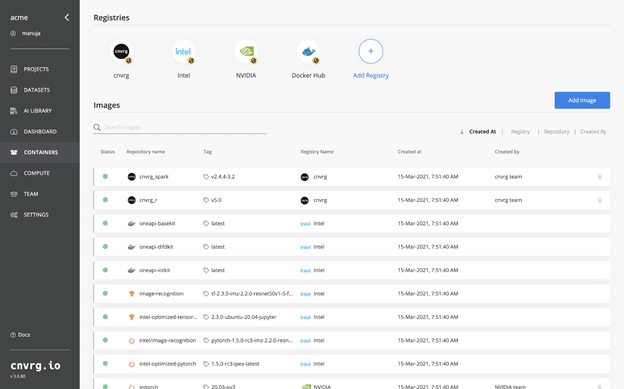
Teams can achieve accelerated performance of many popular ML or DL frameworks in one click on any compute resource available. The cnvrg.io platform delivers Intel’s new managed portal of containers and solutions ready for XPU’s with the new oneContainer integration. Intel’s oneContainer Portal offers containerized software and software stacks including access to Intel oneAPI toolkits across domains such as AI, HPC, and IoT. Users can now run Intel’s production-ready containers and solutions directly from cnvrg.io, including hundreds of ML and DL frameworks, Kubernetes packages, AI models, and pipelines.
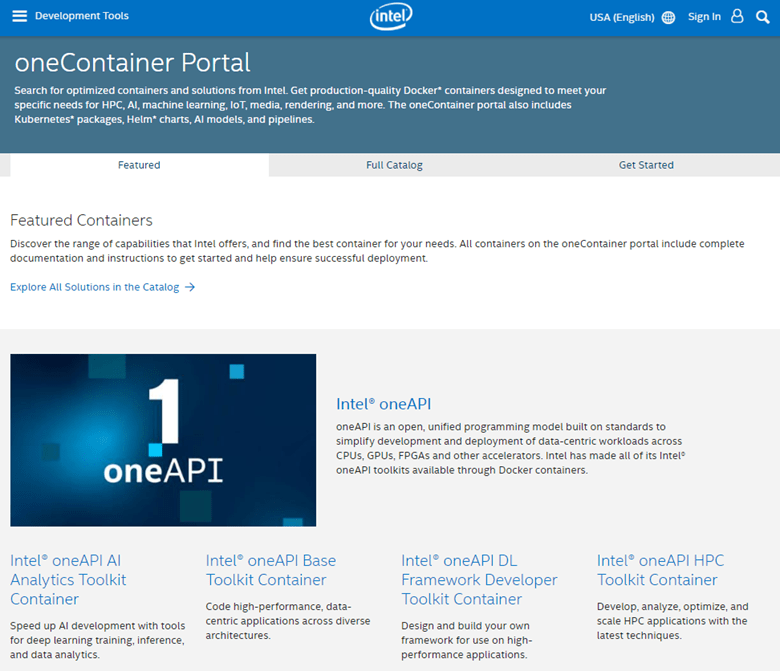
Intel’s fully managed registry of optimized containers can significantly improve performance of analytics workloads and inferences. These containers can run on any compute resource available to them, whether on premise or cloud, accelerating time from research to production.
Production-ready AI frameworks at your fingertips
cnvrg.io gives you one-click access to the large selection of Intel’s oneContainer solutions for acceleration across your AI workflow. The containers are ready-to-run with all necessary dependencies, so you can run them with minimal engineering effort. Integration with the oneContainer catalog of oneAPI solutions makes Intel’s oneContainer Portal a powerful tool that helps data scientists and ML engineers improve and accelerate their pipelines. With the help of cnvrg.io MLOps solutions, data scientists can launch many popular AI frameworks while cnvrg.io takes care of the “plumbing” and configurations.
Optimize analytics and inference workloads
cnvrg.io users gain instant access to Intel’s oneContainer catalog that is fully managed and updated by Intel container development teams to make sure you’re running at high performance. With optimized packages for the latest data science and analytics tools, and use cases, users can browse and accelerate workloads with little effort. With optimized packages for Tensorflow, Spark, PyTorch, and much more, analysts and data scientists can find many of the tools they need to accelerate their ML pipelines.
Extend resources with multi-cloud and hybrid-cloud capabilities
cnvrg.io helps you utilize all of your compute resources with a flexible multi-cloud and hybrid-cloud infrastructure. The new integration is built to run Intel’s containers on the compute you select (cloud and/or on-premise) resources. cnvrg.io is a Kubernetes-native solution with advanced resource management that enables enterprises to expand resources and save on cloud costs. IT admin teams can view pipeline performance and KPI metrics with the automated compute dashboard.
Just select your Intel container from the dropdown when creating new jobs. It’s that easy!
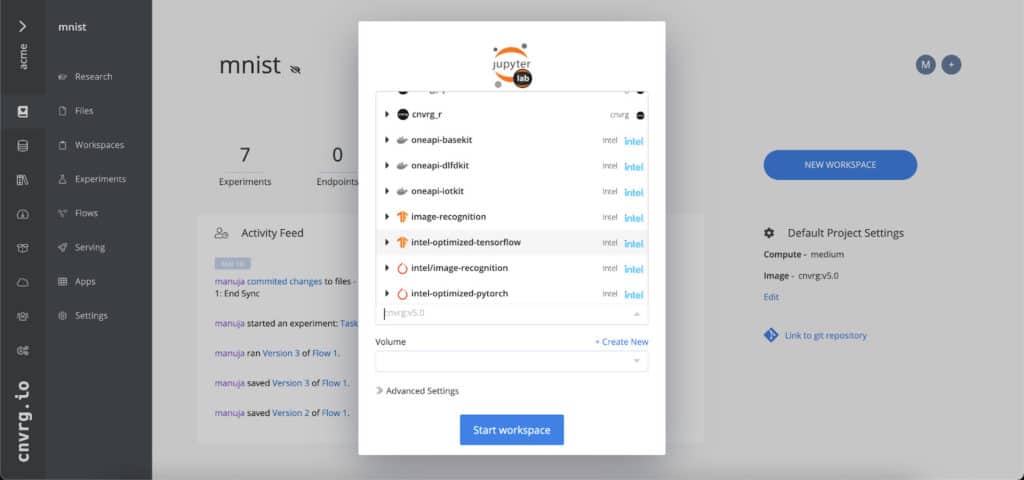
Try a cnvrg.io demo and check out the oneContainer Portal integration and other features helping you to operationalize your machine learning models and improve your compute-resource utilization.







