
Code-First ML Platform
Build advanced algorithms with ability to use custom code anywhere in the ML pipeline

Version Control
End to end version control of project files, artifacts, datasets and full ML pipeline runs

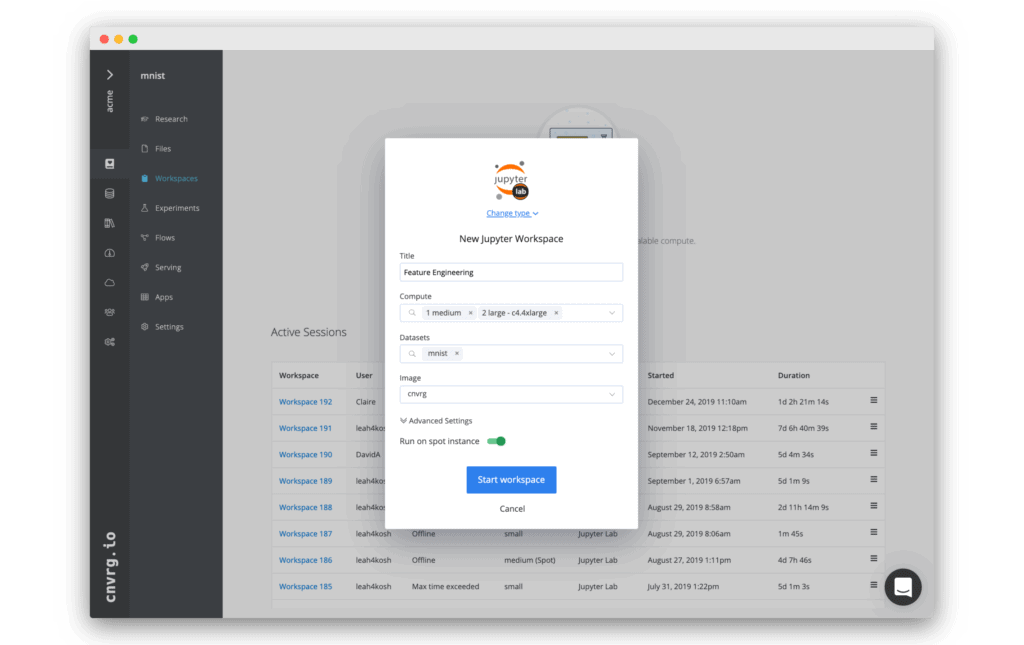
Interactive Workspaces
Built-in support for JupyterLab, JupterLab on Spark, R Studio and Visual Studio Code to run on remote computes

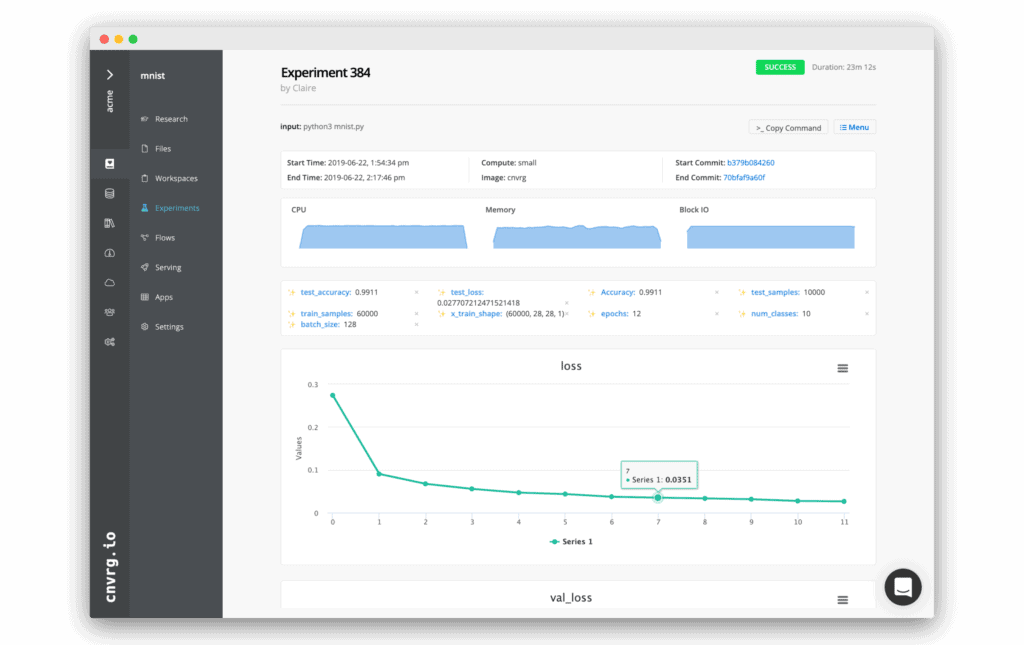
Rapid Experimentation
Run, track and compare multiple experiments in parallel with a single command with grid searches and hyperparameter optimization

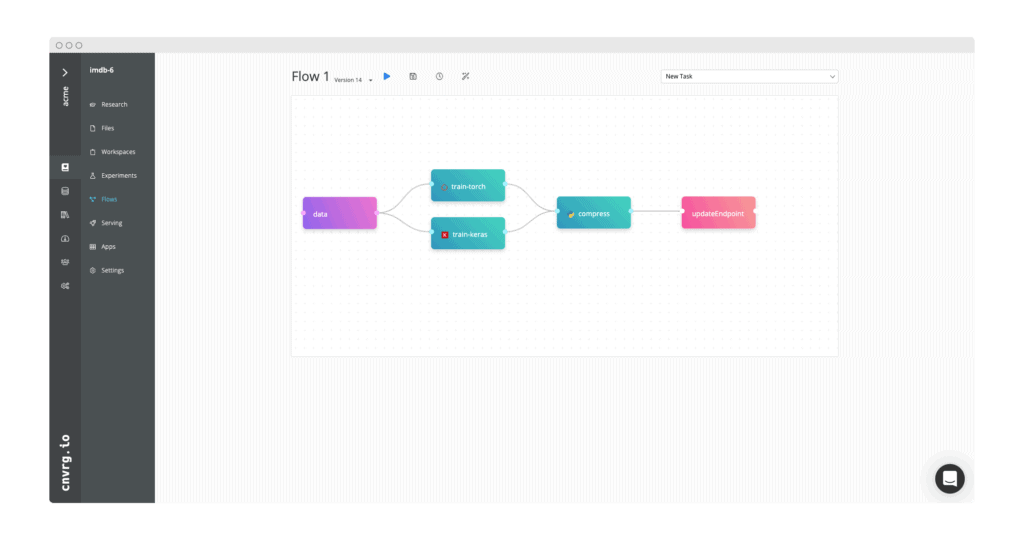
ML Pipelines
Production-ready drag and drop ML pipelines to run your ML components quickly and easily

AI Library
Reuse algorithms, pipelines, and ML tasks with a modular code component package manager

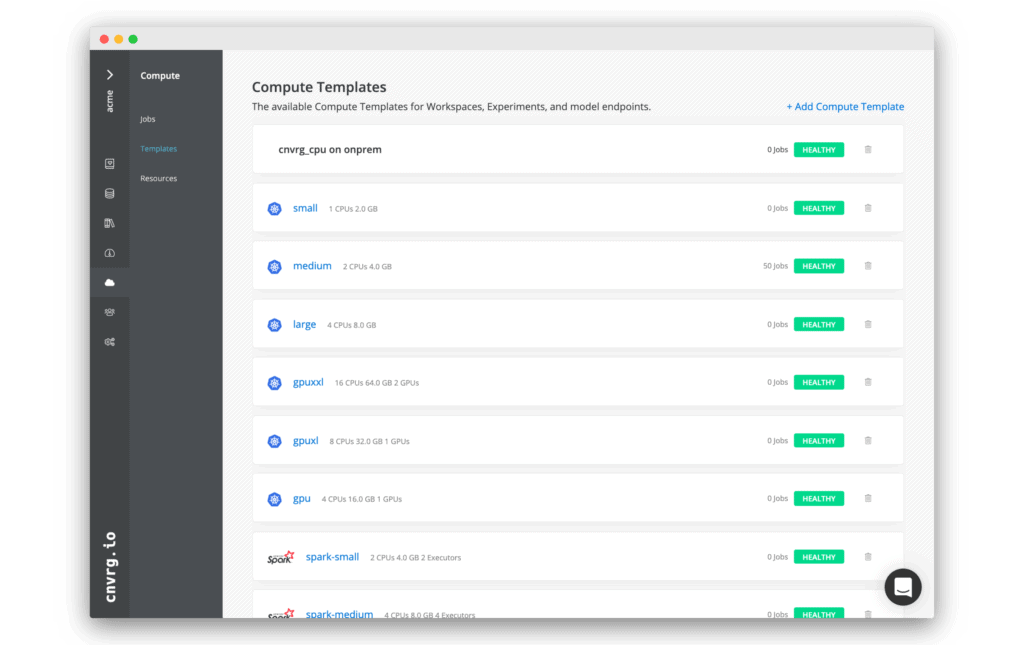
Resource Management
Instantly run pre-configured any compute whether Kubernetes, Spark or On premise and monitor with dashboards

Model Deployment
One click model deployments on Kubernetes via web service, Kafka streams or batch predictions

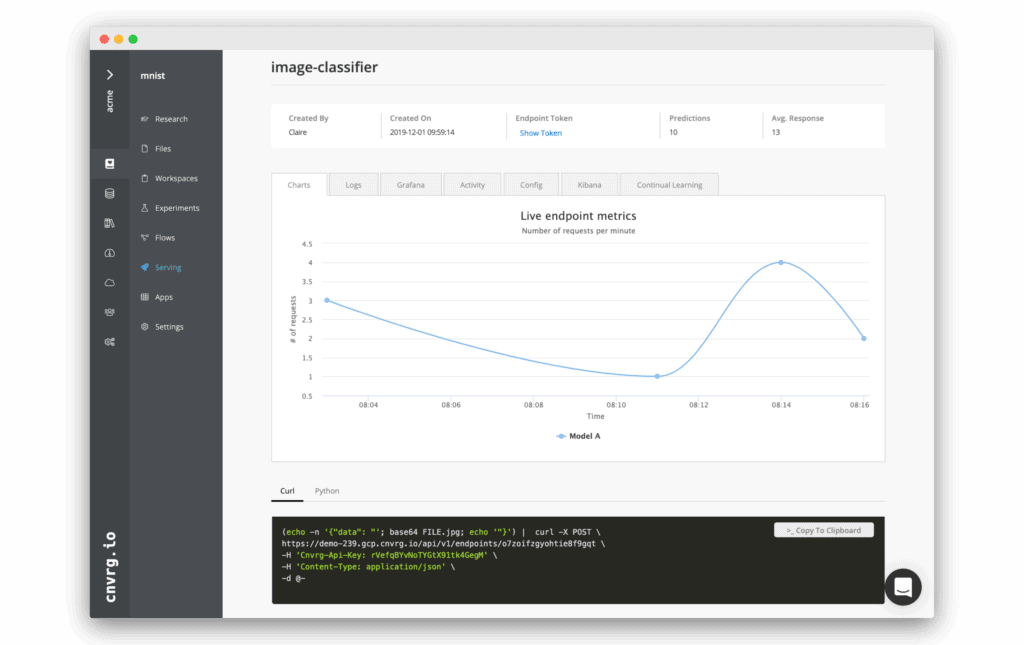
Model Monitoring
Monitor model performance via live charts showing traffic, latency, drift and accuracy

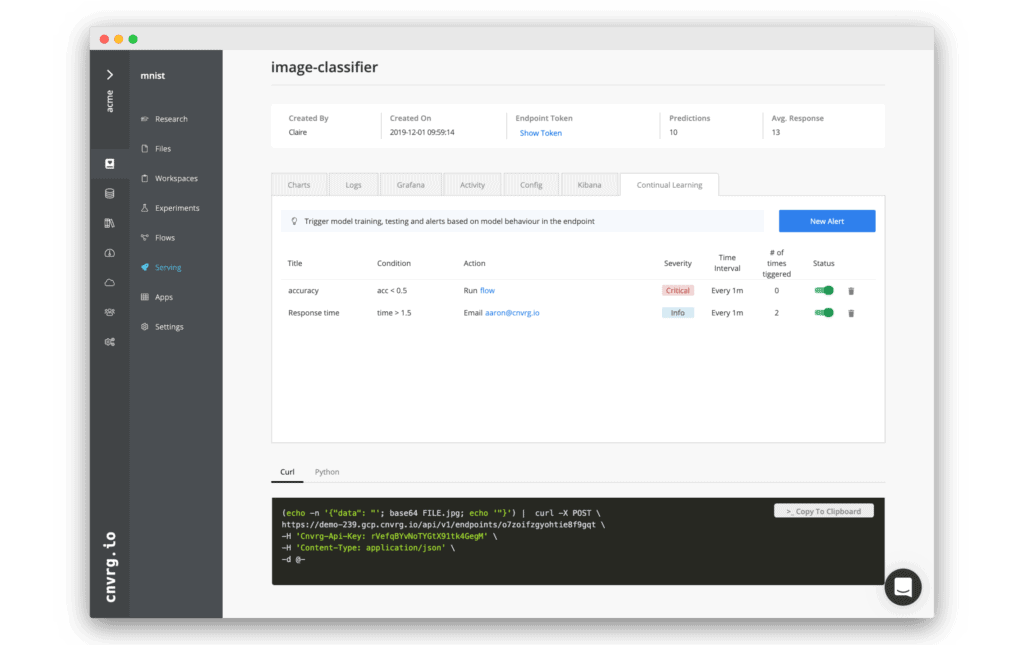
Continual Learning
Create feedback loop with advanced retrain triggers to improve models in production

Automated Model Containerization
Open container-based platform offers flexibility and control to use any image or tool

Scalability
cnvrg.io grows with your organization, to help you deliver more models, easily adopt more compute and the industries latest tools and frameworks

Hybrid Cloud and On Premise
Whether your infrastructure is designed for on-prem, multi-cloud, or both, cnvrg.io works across AWS, Azure, Google Cloud, as well as on-premise options

Open & Flexible
Quickly unify all your teams favorite ML tools, frameworks and resources with no vendor lock-in

Model Reproducibility
Easily reproduce results with fully version ML pipelines, datasets and a library of reusable ML components
Resource Management
cnvrg.io provides extensive tools for resource management to help your IT team utilize and control all compute resources