That’s a wrap for mlcon 2.0: The AI and ML developers conference! The action-packed two day event had 50 talks and over 9,000 registrants from 65 countries. If you missed a talk you were interested in, don’t worry! On demand sessions are available on cnvrg.io. This post highlights some of the major announcements and most popular talks from the conference. And if you missed the DJ in the morning, you can check out his set for day 1.
Major Announcements for cnvrg.io: Metacloud and AI Blueprints

Check out the keynote video to learn what’s exciting about cnrvg.io AI Blueprints
cnvrg.io Metacloud is now generally available. It is a managed AI Platform with the unique capability of being able to bring your own compute and storage. The goal of this was to be able to abstract away the compute infrastructure (on-prem, cloud, etc.) and make it available with just a single click for data scientists and developers. In order to make machine learning even more accessible to any ML developer, cnvrg.io surveyed the most difficult challenges in becoming an AI-first organization. From studying these challenges, they discovered that there is a lack of knowledge in AI and bottlenecks for deployments making it more difficult for organizations to become AI driven. cnvrg.io launched a public preview of a new solution called AI Blueprints which is a marketplace of customizable and open source machine learning pipelines ready to use in any application. It is a collection of many pre-built ready to go pipelines so that you don’t have to do the heavy lifting of connecting various machine learning components. To learn more, check out the keynote “Building for ML Developers”.
You can see hands-on examples of the AI blueprints in practice by developers in the two talks “How to become an AI-first Organization with low-code ML” where a developer builds and deploys a fire detection application in just a few minutes. The second session that highlights AI blueprints in action is “Build your own Slackbot that can answer your team’s company questions”.
Most Popular Talk: Fireside chat with Intel CTO Greg Lavender
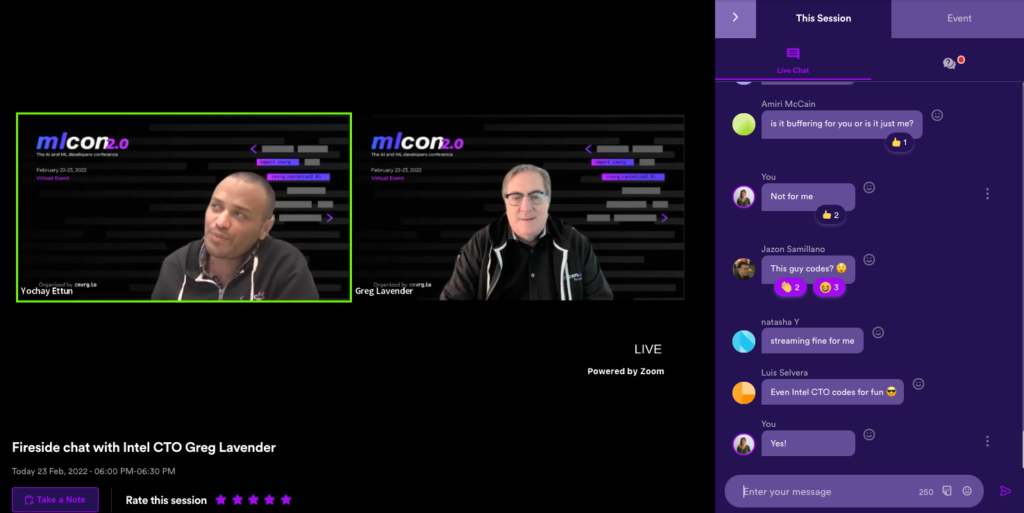
A fun fact Intel CTO Greg Lavender shared is that he still codes for fun.
Undoubtedly, one of the most popular sessions at mlcon was the Fireside chat with Intel CTO Greg Lavender likely because it is rare to hear from a CTO of a large corporation like Intel talk about their ML strategy as well as the latest strategies organizations can take to succeed in AI. This included how to approach security for AI, the importance of low-code/no-code development, and the key to building a hardware and software end-to-end strategy (make developers more productive!) for a complete ML system. The session ended with Greg answering developer career questions which you can check out here. A highlight of the talk was when we learned that Greg Lavender, the CTO of Intel codes for fun. “Even though I am CTO of Intel, with large responsibilities across the company and thousands of engineers working for me, I code for fun not for profit… It’s important to experiment and always take the time to stay ahead of the curve.” which definitely got a reaction from the largely developer audience. So, to answer the chat – yes, even the CTO of Intel codes for fun!
Most Rewatched Talk: Accelerating Transformers Down to 1ms — To Infinity and Beyond! by Jeff Boudier
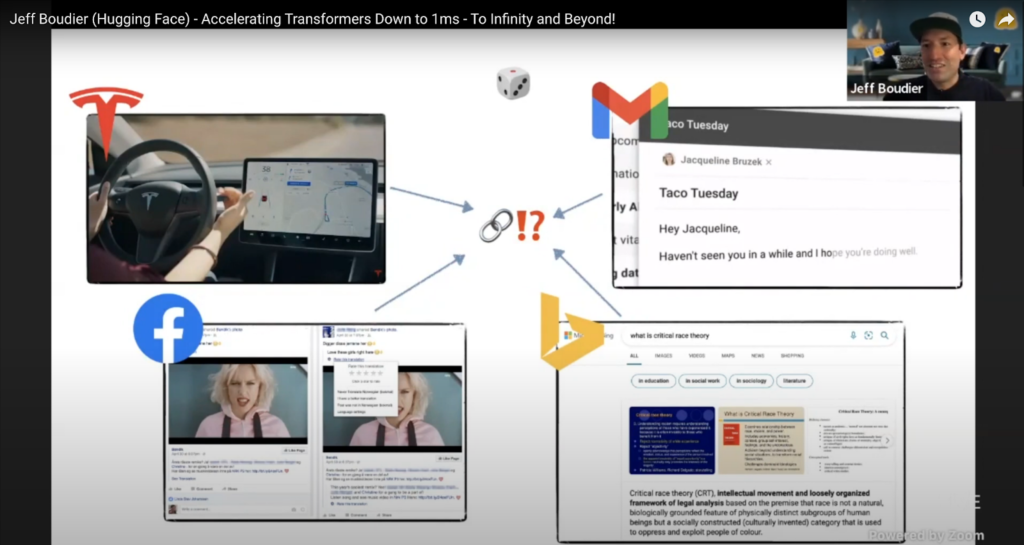
“What do Tesla, gmail, facebook, and bing all have in common? They all have the transformer architecture that powers these machine learning features. They all serve over 1 billion predictions a day on transformer models.”
Everyone wants state of the art model performance. The problem is that few companies have been able to deploy large, complex Transformer models in production at scale. The main bottleneck is the latency of predictions due to size of the models which can make large deployments expensive to run and real-time use cases impractical. Jeff Boudier’s talk went over Hugging Face’s approach in accelerating Transformer machine learning models through research and hardware optimization, to achieve 1 millisecond latency on commodity hardware, and enable any company to deploy these large language models into their production infrastructure, at scale. Note that if you want more details on how they achieve millisecond latency, you can check out Hugging Face’s case study.
Thanks for making mlcon 2.0 a success
We are grateful for the incredibly positive feedback we received from conference attendees. This comment summarizes the general sentiment: “The best thing about this conference for me is to have assembled this great army of superb experts. Is there a chance that you will repeat this totally fantastic feast in the near future?” To answer the question, mlcon 3.0 will happen soon! Stay tuned for more information! Also, if you have any suggestions for the next event, let us know! We value your feedback!

Some awesome people that used the photobooth at mlcon 2.0.