cnvrg.io today announces a new capability of deploying production ML models with Apache Kafka to support large-scale and real-time predictions with high throughput and low latency.

cnvrg.io is thrilled to announce its new capability of deploying ML models to production with an architecture of producer/consumer interface with native integration to Apache Kafka and AWS Kinesis. In one click data scientists and engineers can deploy any kind of model (PyTorch, TensorFlow, SKlearn, XGBoost, Catboost – you name it) as an endpoint that can receive data as stream and output predictions as streams.
This new capability allows engineers to support and predict millions of samples in a real-time environment. This architecture is ideal for recommender systems, event-based predictions, and large-scale applications that require high throughput, low latency and fault tolerant environments.

Every feature in the cnvrg machine learning platform was either custom built for a customers needs or in collaboration with industry data scientists, or was about to be requested by a customer :-). This case is no different. This feature was built out of a need from Playtika BRAIN – a leading team working on AI solutions for Playtika, a Game-Entertainment company dealing with 30 million daily active users (DAU), 10 billion daily events and over 9TB of daily processed data . Playtika’s AI team is taking ML in production to a whole new level with dozens of models in production, automated ML pipelines, scalable architecture and a large team of data scientists.
“We are predicting millions of samples in real time, and found that having a web service is just not enough. This is when we jumped on a call with cnvrg.io and discussed the possibility to package our models not only using REST API, but rather use Kafka Streams for incoming requests and outgoing inferences.”, says Avi Gabay Director of Architecture at Playtika
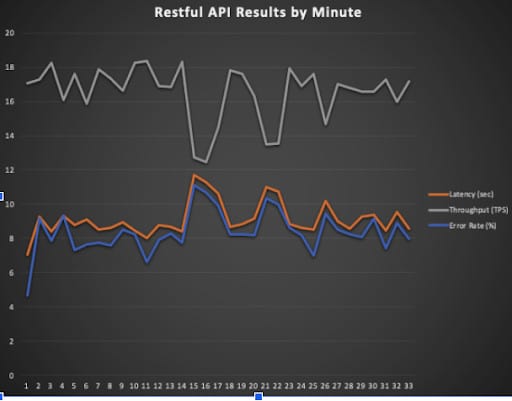
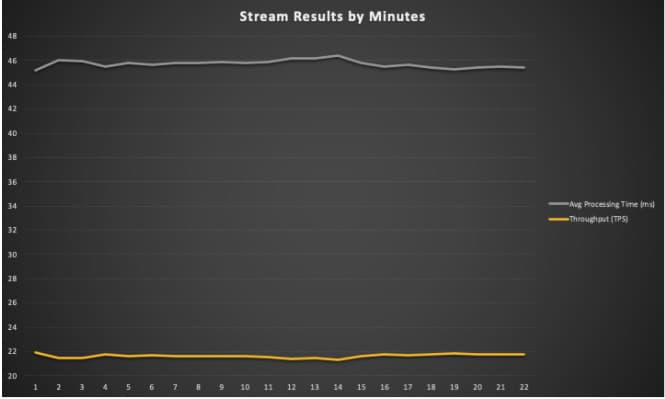
“After a few architecture sessions with the cnvrg team, and a couple of POC sessions, we had a new production environment that fit our scale and needs. From them the first streaming endpoint we deployed through cnvrg, we were able to increase our model throughput by up to 50% and on average by 30% when compared to RESTful APIs”
Comparison
Why choose Streaming Endpoints over Web Services?
Web services are great when you don’t have a lot of requests to serve at the same time. Not only that, but it is also a popular form of deployment because it’s the easiest and fastest solution. All you have to do is spin up a Flask service and you have a full functioning model. But, most large scale enterprises and consumer technologies, a Web Service deployment won’t suffice. The problems begin to occur when you have tons of data coming in every minute. You will see over time that your model will start failing and will send errors back. If you’re lucky and your model is layered on a Kubernetes
architecture you can easily scale the number of pods more and more. This will cause you to eat up much more resources, and will likely require you to implement retries mechanism. Nevertheless, you’ll also need to store your inputs and outputs for each model – meaning you need to add another layer of architecture on top of it. In terms of efficiency and scalability, Web Services fall short and often end up spiraling into more and more errors.
This is where Streaming Endpoints shine. While streaming your data to your model – you will be able to handle 30% more requests for each pod. In addition, you don’t need to handle errors simply because you won’t have any! You can also scale up the number of pods that listen to your Kafka inputs, and all the inputs/outputs are stored in the Kafka topics – so you can always come back to it and understand it.
Streaming Endpoints are a great solution for consumer technologies and large scale applications. This architecture is ideal for recommender systems and event-based predictions that require high throughput, low latency and fault tolerant environments.
Get started for free with our community version – cnvrg.io CORE