


With MIG integration, NVIDIA A100 Tensor Core GPU delivers multiple instances of a single GPU on demand for ML/DL workloads in one click
GPUs are the powerhouses of machine learning and deep learning workloads. And now, with the release of the NVIDIA DGX A100 systems, which are built with eight NVIDIA A100 Tensor Core GPUs, performance and capabilities for AI computing have skyrocketed, providing unprecedented acceleration at every scale and enabling data scientists to focus on innovation. While many ML workloads continue to scale, both in size and complexity, some acceleration tasks aren’t as demanding, such as early-stage development or small batch inference. Infrastructure managers aim to keep resource utilization high and provide GPU access to every user. An ideal data center accelerator doesn’t just accelerate big complex workloads— it also efficiently accelerates many smaller AI workloads. This is where NVIDIA’s new feature called multi-instance GPU (MIG) comes into play.
As data scientists, we understand that NVIDIA’s MIG capability has the power to transform how data scientists work, and opens the possibilities for a significantly wider access to GPU technology. cnvrg.io is announcing today that their OS will be to be the first ML platform to integrate the NVIDIA A100 MIG functionality, in order to expand the utilization of the NVIDIA A100 GPU. Paired with cnvrg.io’s industry-leading resource management and MLOps capabilities for IT and AI teams, MIG instances can now be used in one click by any data scientist performing any ML job. The MIG integration is supported on all NVIDIA A100 GPU servers, for all Premium and CORE users.
What is NVIDIA Multi-Instance-GPU (MIG)?
MIG can partition each A100 GPU into as many as seven GPU accelerators for optimal utilization, effectively expanding access to every user and application. Each instance can run simultaneously, with its own memory, cache and compute resources. That enables each A100 GPU to deliver guaranteed quality-of-service (QoS) at up to 7x higher performance compared to prior GPUs. The A100 in MIG mode can run any mix of up to seven AI or HPC workloads of different sizes. The capability is especially useful for AI inference jobs that typically don’t demand all the performance a modern GPU delivers. Because MIG walls off GPU instances, it provides fault isolation — a problem in one instance won’t affect others running on the same physical GPU.
For example, users can create two MIG instances with 20 gigabytes (GB) of memory each, three instances with 10 GB or seven with 5 GB – all with corresponding amounts of compute. Users create the mix that’s right for their workloads.
With the A100 GPU’s versatility and elasticity, infrastructure managers can maximize the utility of every GPU in their data center to meet different-sized acceleration needs, from the smallest job to the biggest multi-node workload.
This capability essentially turns a single system into a data center with many different instances. The flexibility and variability of configuration options are very broad, with more than 200 permutations of partitioning a single NVIDIA DGX A100 system utilizing different MIG instance sizes (1g.5gb, 2g.10gb, 3g.20gb, etc.). With such immense variability, resource management has the potential to become a nightmare. Infrastructure teams require MLOps, as well as a way to assign, schedule, share and monitor utilization of the MIG resources both within a system and across multiple nodes. This is where the cnvrg.io data science platform was quick to evolve and offer MIG integration with self-service resource management and MLOps capabilities.
How to utilize NVIDIA A100 for ML workloads with MIG, MLOps and resource management
cnvrg.io makes MIG instances available in one click for any data scientist to run any ML job on demand. All the data scientist needs to do is assign a MIG resource (from a pre-curated template menu) to the experiment or workload, just like any other compute resource. The integration with NVIDIA NGC, a hub for GPU-optimized AI software, allows data scientists to simply pull the relevant container for their use case and deploy it on a specific GPU instance.
Behind the scenes, cnvrg.io will schedule the right MIG instance from the pool (with the meta-scheduler), and release it back to the MIG pool when the job is completed. cnvrg.io will also track utilization and constantly monitor the pool of MIG resources so they are available to be meta-scheduled optimally for the data scientist’s workflow. As a design principle, cnvrg.io solves the data scientist configuration pain-points with one-click attachment of MIG instances, and MLOps/DevOps pain points by simplifying onboarding of the A100 GPUs, setting a library of MIG templates, and exposing them for the data scientist.
cnvrg.io supports user friendly GUI, CLI, and Python SDK interfaces. In the video below, we can see how the MIG template is being created by the Admin. With just a few categories to fill out (MIG size, etc.), the template will be ready, and exposed to the data scientists. The configuration options are intuitive, with no complex dependencies or direct calls to the NVIDIA driver level.
Once the MIG templates are ready, they all become part of the MIG pool managed by the cnvrg.io meta-scheduler. From this point forward, MIG instances can be assigned to a job, like any other resource (full GPU, multi-GPUs, multi-nodes, cloud instances) providing the data scientist with the same simple user experience across all different resources. Similar to other ML resources, MIG instances can be located in different DGX A100 servers, and even in a different physical location or data center. All MIG instances will be managed together and offered as one resource pool for the data scientist.
Data scientists familiar with cnvrg.io ML flow design can now assign MIG instances to any component of the ML pipeline. They also can assign multiple resources in a priority list for each component, one of which will be an MIG instance. The MIG instance will be activated based on availability and priority. For example, the data scientist can assign MIG 1g.5gb to the inference task. If all MIG instances (of this type) are busy and not available, the user can request a fallback to an NVIDIA V100 GPU instance in the cloud, and only as a last resort assign the job to a CPU machine.
A flow visualization with MIG instances assignment is shown below. While the Spark job for data prep will be assigned with a full GPU, the TensorFlow-train job which has 18 experiments, each will be assigned with 1g.5gb MIG (total of 18 instances – 1g.5gb A100 MIGs). Mixing the training, analytics and inference is now easy and accessible for the data scientist.
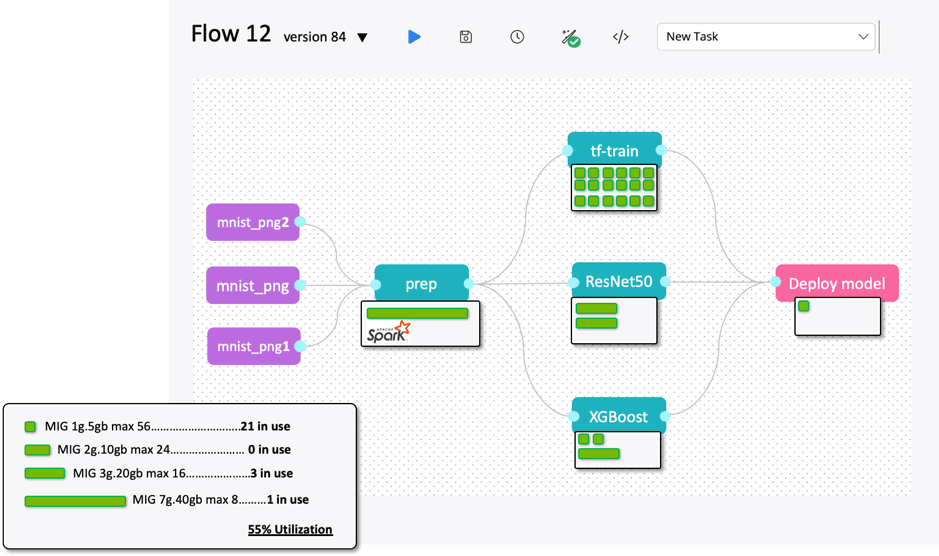
The final dimensions to consider are monitoring, tracking utilization, and reporting. cnvrg.io has implemented a feature-rich dashboard for the DevOps/IT or MLOps engineers. The dashboards create in depth time series charts and track every MIG instance in any machine (local or remote). Data can be exported and used to analyze demand over time, the cross-section of team/projects, utilization and other queries. As each A100 GPU is potentially sub-divided into seven independent compute entities, the utilization tracking can be more complex without proper visualization charts (considering in each node we are now tracking 56 MIG instances, each with a different utilization cycle, and not just eight A100 GPUs). cnvrg.io has implemented an intuitive dashboard that presents actionable data for consumption of MIG instances, availability and assignments.
AI teams can drastically improve utilization of their NVIDIA DGX A100 systems with MIG and cnvrg.io. The cnvrg.io data science platform is certified under the NVIDIA DGX-Ready Software program and can give you the tools to improve performance and utilization with advanced resource management and MLOps.
Learn more in a one on one demo with an ML expert.






