

.png?width=770&name=Copy%20of%20Webinar%20-%20Continual%20Learning%20(7).png)
What is continual learning?
Academics and practitioners alike believe that continual learning (CL) is a fundamental step towards artificial intelligence. Continual learning is the ability of a model to learn continually from a stream of data. In practice, this means supporting the ability of a model to autonomously learn and adapt in production as new data comes in. Some may know it as auto-adaptive learning, or continual AutoML. The idea of CL is to mimic humans ability to continually acquire, fine-tune, and transfer knowledge and skills throughout their lifespan. As you know, in machine learning, the goal is to deploy models through a production environment. With continual learning, we want to use the data that is coming into the production environment and retrain the model based on the new activity. For example, we’ve all experienced Netflix’s highly successful recommender system for “Up Next”. Netflix recommender system suggests a show directly after your last episode has ended, and is normally hard to resist as the seconds drop. That kind of model in production is something that needs to be retrained periodically because there are new movies, new tastes, and new trends in the market. With continual learning, the goal is to use data that is coming in, and use it to automatically retrain the model, so you can really gain high accuracy and retain high performing models.
Why do we need continual learning?
The answer is pretty simple – data is changing. Data could be changing because of trends, or because of different actions made by the users. For example, Amazon best sellers from the year 2000, was the Harry Potter book. Today, you might be surprised to find out the best seller is a completely different genre: Fire and Fury: Inside the Trump White House.

So, Amazon would have to retrain the model and recommend new books to their customers based on new data and trends. A bit more updated example is the bitcoin price before the huge drop. In 2017, the bitcoin was worth $19K. About a month and a half later, it dropped to $6K.
Not only is data changing but, researchers have expressed that “lifelong learning remains a long-standing challenge for machine learning and neural network models since the continual acquisition of incrementally available information from non-stationary data distributions generally leads to catastrophic forgetting or interference.” The case for continual learning remains strong. For data scientists, continual learning will ultimately optimize models for accuracy, improve model performance, and save retraining time by making models auto-adaptive.
Machine learning pipeline with continual learning
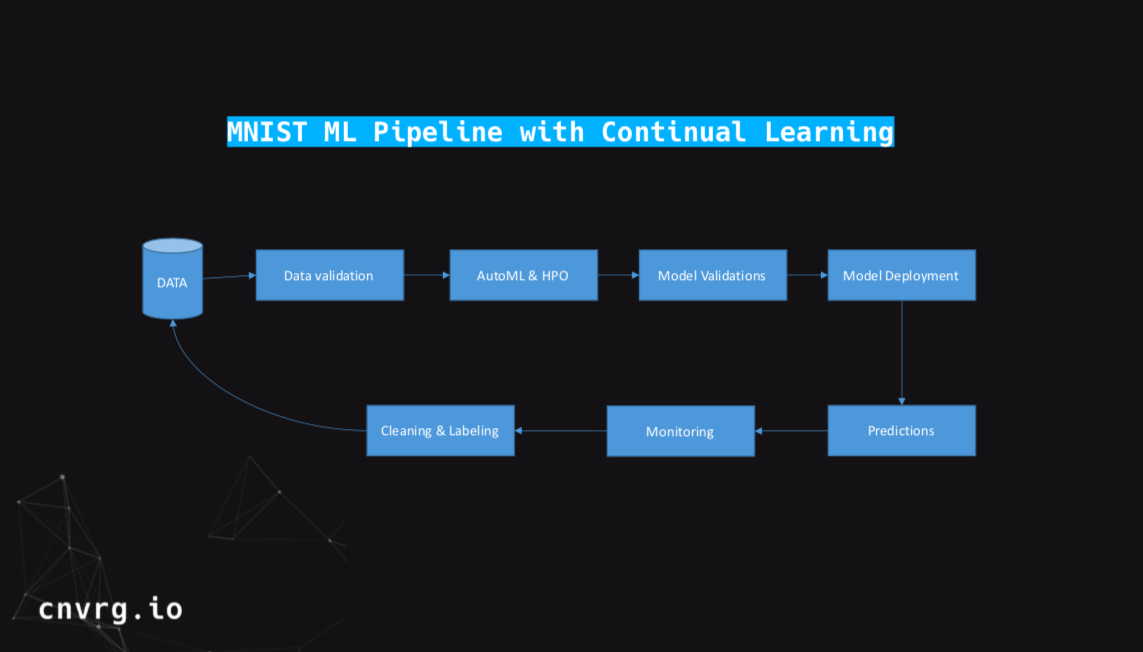
The diagram above illustrates what an ml pipeline looks like in the production environment with continual learning applied. You’ll notice that the pipeline looks much like any other machine learning pipeline. We must have the data, some sort of validation. This could include tests, or internal benchmarks such as determining the quality of data. It could also be pre-processing that you operate.
Next, in the pipeline is AutoML. AutoML in continual learning is a very important part of the pipeline and is similar to the training step in a typical machine learning pipeline. But, we will touch more on that later.
After training, you’ll do some model validations to test the models, and make sure all of them are working well. Here you can also pick the best one, and deploy it to the production environment. Thus far, the pipeline looks like a classic machine learning pipeline. In order to apply continual learning we add monitoring and connect the loop back to the data.
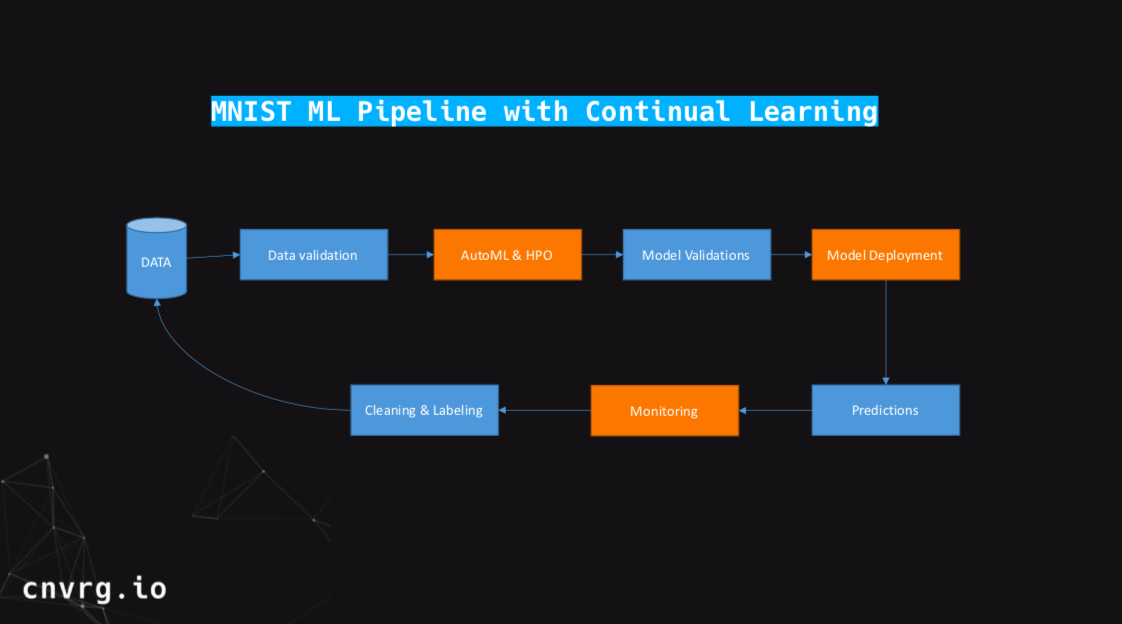
Predictions that are being collected in the model deployment area will be monitored. Once monitored you will clean the data and label it if required. But, for something like a recommender system or forecasting, you’ll just be able to close the loop without the human labeling. After labeling and cleaning the data, we’ll move it back to the data to repeat the training and validation process again. Now we have closed the loop like a flywheel.
AutoML in the continual learning pipeline
AutoML is an important component for applying continual learning because we are working with a constant stream of data. You could keep it simple and just retrain the same algorithm with the same parameters, but because we still want to gain really high accuracy we’re going to use AutoML.
AutoML doesn’t have to be really complicated meta learning. You can just use hyperparameter optimization, open-source algorithms and frameworks — and you’ll be surprised how simple it is. As part of your research, when you start working on your machine learning pipeline, you’ll have to select your algorithm space. For example, if you’re doing a computer vision problem, might want to use transfer-learning as the training algorithms. With transfer-learning, you have a lot of pre-trained models that you can use to retrain only the last layer of the network, and then have your model deployed.
In this case, you’d select one of the popular pre-built models like VGG, Inception, ResNet and a few others. For each model, we also have to specify its range of parameters.
This could turn into a really big computational problem. It is up to you as a data scientist to really research what kind of algorithm and parameters are going to be useful for your machine learning problem.
AutoML links: AutoKeras, Auto SciKitLearn, FeatureTools for feature engineering
Track your AutoML
With AutoML, it is especially crucial to track not only the models in production, but the entire process. If you put your machine learning on autopilot, you have to make sure that everything is tracked and managed. You need to track everything from: the kind of algorithm you are using, what the hyperparameters are, the kind of compute being used, the memory consumption, metrics, accuracy, and so on. Let’s say you are training 60 different experiments today. The data being tracked might be used for next week when trying to re-deploy and retrain the model.
You can also use the information for meta learning, to try to understand what kind of algorithms are working well for the problem, which will minimize the number of experiments each time.
Automate your infrastructure
Another critical thing about AutoML – especially with deep learning – is automating your machine learning infrastructure. It can take a lot of time to spin up a deep-learning ready instance (think CUDA, dependencies, data, code, and more). We recommend using Kubernetes on top of all your preferred cloud providers. The fact that you’ll have a Kubernetes cluster up and running makes it really easy to deploy new experiments. Using Kubernetes, you can launch many experiments very quickly and track them to make sure all experiments are running well.
Keep in mind though, that maintaining a Kubernetes cluster is not that simple and might require extra help from your IT/Data engineering team.
Deploying models in a continual learning pipeline
Once you’ve trained and chosen the model with the best performance, your model will be ready for deployment. One major challenge with continual learning is how to deploy new models to the same environment without negatively affecting users experience and maintaining high accuracy.
Deploying models for continual learning is a bit different from classic model deployment. Usually, even a data scientist will be able to deploy a model, but since this is going to be automated, we have to do it very carefully. Just as you won’t deploy a software that has a bug to a production environment, you wouldn’t deploy a model that was not trained and validated successfully. To be sure that your new model is working well, you’ll test it on old data before and during deployment. Additionally you’ll want to monitor performance and health of your system.
Now, in software development, there’re a lot of different ways to deploy new software.For machine learning, this field is still pretty new, but we recommend using the Canary deployment technique. Canary is a technique to introduce new software version in a way that effect’s users in parts, gradually increasing the number of users based on the tests. Using this technique, is going to gradually deploy the model to larger subsets of users.
On the implementation level — we recommend using Kubernetes alongside Istio for model deployment, so you can do A/B testing, and make sure that your model is deployed well. We also have a guide on our blog on how to deploy machine learning models using Kubernetes.
Monitoring of continual learning pipelines
Monitoring is an especially important part of machine learning with continual learning. You need to make sure that if something bad is happening to your model, or if the data that is being sent to your model is corrupted, that you have a mechanism to be alerted.
Most often, a single data scientist will manage several machine learning pipelines at a time. So the alert setup is crucial. Once you deploy the new model to the production environment, the goal is to provide the data scientist or data engineer with the control and transparency they need to monitor the machine learning model. For the ability to automatically deploy new versions of the model, you have to monitor the input data to detect data drifts and anomalies. Monitoring is also important for prediction data to ensure high performance and accuracy.
There are great tools in Kubernetes, or Prometheus alongside AlertManager that you can use to monitor all the input data. And you should utilize cloud services and Kubernetes to automate your machine learning infrastructure and experimentation.
Triggering and retraining your model for continual learning
The last step in a continual learning ML pipeline is to trigger the retraining and closing the loop. Your ML pipeline is prepared for continual learning:
- You have the data
- Experiments are running the training
- Predictions are being collected and monitored
- The new data is being cleaned
Next, you must decide the triggers for retraining your model. There are several ways to do that. We have customers that retrain their model periodically. For example, for recommender systems or ads, we saw teams that retrain every 30 minutes. You might also consider retraining the model only on new data that is coming in.
Other ways are to track and monitor model decay and model bias, low confidence and any kind of other alert in the production environment that triggers retraining. The most important thing is that if you trigger the machine learning pipeline automatically, you should track and validate the trigger. Not knowing when your model has been re-trained can cause major issues. You should always have control of the retraining of your model, even if the process is being automated. That way you can understand and debug the model in the production environment.
Closing the ML loop
Once your AutoML, deployment and monitoring systems are in place, you’ll be able to close the machine learning loop. Your models will be running with continual learning, and autonomously adapt to new data and trends. Not only will your model accuracy be automatically improving, but overall you’re model will be performing better in the application.
Want to learn how to make your machine learning models Auto-Adaptive? Watch a webinar on Auto-Adaptive Machine Learning







