


In recent years, Deep Learning (DL) techniques have evolved greatly. The number of companies using this technology is growing annually because DL can be applied to various tasks throughout multiple spheres. However, despite the rapid development of the artificial intelligence (AI) sphere and some technological advances being made for the last few years, Deep Learning is still considered a very expensive AI function both in time and computation-wise.
Nevertheless, there are many ways and approaches to accelerating the Deep Learning training process and making it more efficient. Still, all of them require training on a graphics processing unit (GPU).
In this article we will talk about:
- What is a GPU?
- The principles of GPU computing
- Models of parallelism, general purpose GPU programming
- How deep learning frameworks utilize GPUs?
- CPU vs. GPU
- What is a CPU?
- How do GPUs work?
- FPGA and ASIC accelerators
- What is an ASIC?
- What is an FPGA?
- Pros and cons of using ASICs and FPGAs for deep learning
- How to choose the best hardware device for deep learning?
- Benefits of using GPUs for deep learning
- How to choose the best GPU for deep learning?
- GPU market overview
- Selecting the right resources for your task
- Consumer-grade GPUs
- Best deep learning GPUs for data centers
- DGX for deep learning at scale
- What is the best GPU for deep learning?
- Metrics to monitor GPU performance
- Actions you can take to improve GPU utilization
- How to use GPU for deep learning?
- What is CUDA?
- What is cuDNN?
- How to train on GPU with PyTorch?
- How to train on GPU with TensorFlow?
- How to train on GPU with Keras?
- How to train on GPU with MxNet?
- Using distributed training to accelerate your workload
- Data parallelism
- Model parallelism
- Multi-GPU
- Synchronization methods
- Deep Learning on GPU clusters
- What is Mixed Precision?
- What is NVIDIA SDK?
- Cloud services vs. On-premise approach
- Best practices, tips, and strategies
Let’s jump in.
What is a GPU?
Graphics Processing Unit (GPU) is a specialized processor that was originally designed to accelerate 3D graphics rendering. However, over time it became more flexible and programmable which allowed developers to broaden the horizons and use GPUs for other tasks. The greatest strength of a GPU is the ability to process many pieces of data at the same time. This makes GPUs quite useful devices for machine learning (ML), gaming, and video editing.
Nowadays, a GPU is one of the most important types of computing technology that is widely used for both personal and industrial purposes. Despite GPUs being the best known for their gaming capabilities, they are in high demand in AI as well.
From the hardware point of view, a GPU can be integrated into the computer’s central processing unit (CPU) or be a completely discrete hardware unit. When talking about a discrete hardware unit the term graphics card or video card might be used to replace the GPU term. However, it is worth mentioning that though these terms often interchange with one another, a GPU is not a video card.
Let’s make this clear. The GPU is just a part of the video card. The concept is the same as with a motherboard and a CPU. The graphics card is an add-in board that includes a GPU and various components that allow a GPU to work correctly and connect to the rest of the system.
The principles of GPU computing
Knowing what GPUs are in general, let’s talk about why they are in high demand in deep learning. The reason behind that is simple. GPUs can effectively parallelize massive computational processes.
Models of parallelism
As mentioned above, the greatest advantage that comes with a GPU is the ability for parallel computing. Nowadays, there are four basic approaches to parallel processing:
- Single instruction, single data (SISD) – only one operation is performed over one piece of data at a time
- Single instruction, multiple data (SIMD) – single operation is performed over multiple pieces of data at a time
- Multiple instructions, single data (MISD) – several operations are performed over one piece of data at a time
- Multiple instructions, multiple data (MIMD) – several operations are performed over multiple pieces of data at a time
A GPU is a hardware device with SIMD architecture. Thus, a GPU fits deep learning tasks very well as they require the same process to be performed over multiple pieces of the data.
General purpose GPU programming
Since the launch of NVIDIA’s CUDA framework, there is no barrier between the developers and the GPU resources. Nowadays, developers do not need to understand specialized GPU programming languages. Thus, GPU’s processing power was quickly applied to deep learning tasks.
How deep learning frameworks utilize GPUs?
As of today, there are multiple deep learning frameworks such as TensorFlow, PyTorch, and MxNet that utilize CUDA to make GPUs accessible. They offer a high-level structure that minimizes the complexity of working directly with CUDA while making GPU processing a part of modern deep learning solutions.
CPU vs. GPU
As you might know, there are two basic neural network training approaches. You might train either on a CPU or a GPU. As mentioned above, training on GPUs accelerates the training process. It is time to find out why this is happening.
What is a CPU?
The Central Processing Unit or CPU is considered to be the brain of the computer. It executes almost every process your computer or operation system needs. From the hardware point of view, the CPU consists of millions of transistors and can have multiple processing cores.
Nowadays, most CPUs have multiple cores which operate with the MIMD architecture. This fits the CPU’s philosophy perfectly as the computer’s brain must be able to execute different instructions on different data at the same time.
Overall, the CPU is the major component of your computer that handles the computer’s operation logic.
How do GPUs work?
At this point, you understand the basics of a GPU and a CPU, their roles, and key capabilities. Now, let’s move on and discuss how they work so we will be able to identify the advantages of the GPU over the CPU in deep learning tasks.
It is worth mentioning that CPUs are latency optimized while GPUs are bandwidth optimized. So, for example, you can imagine that a CPU is a reactive plane while a GPU is a cargo plane. If you have the task of transporting a number of packages from point A to point B, your CPU being an extremely fast reactive plane will be able to deliver some of them very quickly. Still, the CPU will go back and forth numerous times as it cannot take many packages aboard. Now imagine that the packages are actually some memory and you need to transport it to your RAM. As shown above, the CPU is good at fetching small amounts of memory quickly. On the other hand, the GPU being a cargo plane is slower in doing that but can fetch much more memory at once.

A CPU tends to have less memory bandwidth than a GPU. That is why the more memory your computational operations require the more significant the advantage of GPUs over CPUs. When speaking about neural networks the most computationally demanding piece in the training process is multiple matrix multiplications which take up a lot of memory.
Still, there is a latency problem. The GPU cargo plane might be able to deliver a large amount of memory at once but it will take some time for it to return to the initial point and deliver the remaining part. Fortunately, the GPU solves this problem by using multiple cargo planes at once which helps to effectively hide latency. It is called thread parallelism. In theory, we could hire many reactive planes to deliver the packages but in practice, there is no real benefit of this scenario.
This is actually the reason why GPUs are used to train deep learning models. For a large amount of memory, GPUs provide the best memory bandwidth while having almost no drawback due to latency via thread parallelism. It is that simple, GPUs are simply faster.
Overall, it is worth mentioning that despite CPUs and GPUs having a lot in common, they have unique strengths. The CPU is a powerful execution engine that is suited to a wide variety of workloads, especially those for which latency or per-core performance is important. Still, for Deep Learning tasks GPU tends to save you a fair amount of time compared to the CPU.
FPGA and ASIC accelerators
However, other hardware devices can be used to train a neural network as well. For example, sometimes you might face strange abbreviations like an FRGA or an ASIC. Let’s talk in-depth about these devices and once and for all decide which hardware device should be used when working on a Deep Learning project.
What is an ASIC?
An application-specific integrated circuit (ASIC) is an integrated circuit chip customized for a particular use rather than intended for general purpose use. For example, a chip designed to run in a digital voice recorder is an ASIC. In general, ASICs require a lot of development time and are very expensive to design and fabricate. There are many names for these chips but the most commonly used is TPU (Google TPU). If you are familiar with Kaggle you know that it provides an ability to turn on the TPU accelerator in your notebook.
So, ASICs are very interesting devices that can outperform GPUs due to their more specialized nature. However, for private usage, you do not need an ASIC even for complicated DL tasks. You will be more than fine with a GPU. Still, if you want to access TPUs you can use Kaggle accelerator or Google Cloud.
What is an FPGA?
Field programmable gate arrays (FPGAs) are integrated circuits with a programmable hardware fabric. FPGAs are a great and cheaper alternative to ASICs as the circuitry inside a chip is not hard etched and you can reprogram it for a specific task. FPGAs deliver the needed performance without the cost and complexity of developing ASICs. Still, you must be able to reprogram them in order to unveil their true potential.
Pros and cons of using ASICs and FPGAs for deep learning
Now when you understand the basics of ASICs and FPGAs let’s talk about the pros and cons of using them for deep learning.
Pros for ASICs:
- Designed for a specific deep learning workload
- Show great performance
Cons for ASICs:
- Have a long production cycle time (12 – 18 months)
- Very expensive
- Not flexible
Pros for FPGAs:
- Reprogrammable devices
- Flexible
- Cheaper than ASICs
- Show performance comparable to ASICs
Cons for FPGAs:
- Very difficult to program
- Reprogramming can take from several hours to several weeks
- Still pretty expensive comparing to GPUs
How to choose the best hardware for a deep learning project?
As mentioned before, there are four hardware devices to choose from for your deep learning project:
- CPU
- GPU
- ASIC (TPU)
- FPGA
It is more or less easy with the CPU. In general, a CPU is not used to train deep learning models as it will not deliver the necessary performance. Still, on the preprocessing, inference, and deployment stages of a DL project, a CPU is a commonly used hardware device. Moreover, if you think of the cost/performance ratio, you can often afford multiple CPU infrastructure for the same price or less than the cost of a single GPU. That is why you should explore your opportunities before you make a final choice.
As for the rest of the list, that is when things get really tricky. If you want raw performance power then ASICs are the devices you might want to look into. ASICs are built for a specific deep learning workload. That is why they will excel at it. However, it can be difficult to access them. You might even need to spend some money to get access to the Google Cloud, for example.
As for FPGAs, they are not as popular as GPUs or even ASICs. Despite FPGAs having the potential to deliver performance similar to ASICs, they need to be programmed first to do so. That is an additional obstacle because you need to learn how to do that. Thus, it might be hard to unveil FPGAs true potential.
On the other hand, GPUs are almost everywhere simply because each personal computer must have a video card. I am sure you have one on your computer. An enterprise-grade solution can be a GPU cluster or a cloud service with access to the GPUs. GPUs are great in parallel processing and can deliver incredible acceleration in cases where the same operation must be performed many times in rapid succession.

That is why the only true competitors to GPUs right now is ASICs. Still, GPUs are more commonly used due to easier access.
Benefits of using GPUs for deep learning
If you have chosen a GPU as your hardware device for your next deep learning project, you can be sure that:
- Your machine learning operations will run faster than on CPU
- Your training process will be distributed
- You will work with a large memory bandwidth
- You will be able to process large datasets faster. The larger the dataset the greater benefit you can gain from using GPUs
- You will be able to use some advanced techniques to enhance the performance even more
How to choose the best GPU for deep learning?
At this point, you understand the basics of GPUs and know the benefits of using them as your hardware device for a deep learning project. Now it is time to figure out what to look out for when choosing a GPU for a deep learning project.
Let’s start with the obvious one. As mentioned above, GPUs benefit from a large memory bandwidth. That is why you should pick a GPU with the highest bandwidth within your budget. Also, you should pay attention to the number of cores as it determines the speed at which a GPU can process the data. The higher the number, the better. This is especially crucial if you plan to work with large datasets.
Moreover, please pay attention to the video RAM size as it is the measurement of how much data the GPU can handle at once. Last but not least, you must check the processing power because it shows the speed at which the GPU can compute the data which determines how fast the system will perform tasks.
Overall, you need to pay attention to memory bandwidth, the number of cores, video RAM size, and processing power. The higher each of these indicators, the better. Still, please stay within your budget as GPUs can be quite expensive.
GPU market overview

As you might know, there is a variety of GPUs on the market, still, the NVIDIA solutions tend to be the most popular and powerful. However, in 2020, AMD has made a massive step towards being a strong competitor in the GPU market. Some analysts believe that over the next few years the GPU market might change a lot. Nevertheless, as of today, AMD GPUs are decent for gaming but as soon as deep learning comes into the picture NVIDIA is the best option that provides all grades of GPUs. Moreover, NVIDIA’s CUDA tool is used by the majority of modern deep learning frameworks to work with GPUs.
Among the NVIDIA offers you can find:
- Consumer-grade GPUs (basically they are GPUs for personal usage)
- GPUs for data centers
- DGX systems
Selecting the right resources for your task
It is always better to identify the complexity of the deep learning tasks you want to perform on a GPU to choose a proper one. Let’s make this clear. You should not buy the most expensive and powerful GPU on the market as you might simply never use its true power. On the other hand, you should not buy the cheapest one as it might not fit well on your tasks. Also, there might be budget issues as GPUs can be pricy. Thus, some tips can help you.
- You must figure out what your current video card model is. You might not need a new GPU at all
- If you want to use a GPU for studies or to train simple and small deep learning models you don’t need the latest video card. You will be good with some low-end GPU, for example, NVIDIA’s GEFORCE GT 930M. In general, any GPU older than 2015 will fit well on light tasks
- If you want to train large and complex models and solve difficult deep learning problems you need to think of the latest GEFORCE lineup, for example, NVIDIA GEFORCE RTX 3090 or even a more powerful TITAN lineup. On the other hand, you can use cloud services that provide access to powerful GPUs.
- If your task is complex enough that it requires GPU parallelism, you must think of a deep learning infrastructure that supports multi-GPU processing and has multiple high-end GPUs aboard. On the other hand, cloud services that provide access to TPU clusters might be a solution as well.
Consumer-grade GPUs
To tell the truth, it is a bit complicated when talking about the consumer-grade GPUs simply because they are not designed for large-scale deep learning projects. In general, these GPUs are more focused on gaming and entertainment, however, they might be an entry point for deep learning enthusiasts who want to try themselves in the industry.
Still, it is worth mentioning that consumer-grade GPUs are widely used by data scientists. For example, there are AI companies that use computers with consumer-grade NVIDIA GPUs to train massive neural networks. Generally, it happens because of budget issues but this approach can be quite successful.
As of today, the best consumer-grade GPUs on the market are:
- NVIDIA GEFORCE RTX 3090 – as of today NVIDIA GEFORCE RTX 3090 is the most powerful GPU from the RTX 30 series. The GEFORCE RTX 3090 is a GPU with TITAN class performance. It’s powered by Ampere (NVIDIA’s second gen RTX architecture) doubling down on ray tracing and AI performance with enhanced Ray Tracing Cores, Tensor Cores, and new streaming multiprocessors.
- RTX 30 series in general – despite NVIDIA GEFORCE RTX 3090 being the most powerful model from this series the rest of the models are still great for delivering a great deep learning performance
- NVIDIA GEFORCE RTX 2080 TI is the most powerful GPU from the RTX 20 series. Sure it is not as powerful as latest models but its powerful NVIDIA Turing architecture and 11 GB of next-gen, ultra-fast GDDR6 memory (vRAM) as well as a 352-bit memory bus, a 6MB cache, and roughly 120 teraflops of performance make it an ultimate gaming and deep learning GPU
- NVIDIA TITAN V is a GPU designed specifically for data scientists and researchers that provides performance similar to datacenter-grade GPUs for some deep learning workloads. NVIDIA TITAN V is the most powerful Volta-based graphics card ever created for the PC. It has two editions and provides from 12 to 32GB vRAM memory, 4.5 to 6MB cache, and 3072 to 4096-bit memory bus.
- NVIDIA TITAN RTX is comparable to TITAN V. It was designed for researchers, developers and creators and built on Turing architecture, bringing 130 Tensor teraflops of performance, 576 tensor cores, and 24 GB of ultra-fast GDDR6 memory (vRAM).
Best deep learning GPUs for data centers
GPUs for data centers are the standard for deep learning implementations in production. They are designed for large-scale projects and show company-grade performance. That is why most enterprises either build their own computing clusters using such GPUs or rent one.
The best available models are:
- NVIDIA Tesla A100 Tensor Core GPU powered by the NVIDIA Ampere architecture was designed for machine learning, data analytics, and high performance computing (HPC). A100 is the engine of the NVIDIA data center platform. Each Tesla A100 provides up to 624 teraflops performance, 40GB memory, 1555 GB memory bandwidth, and 600GB/s interconnects.
- NVIDIA Tesla v100 Tensor Core is an advanced data center GPU designed for machine learning, deep learning and HPC. It’s powered by NVIDIA Volta architecture, comes in 16 and 32GB configurations with 149 teraflops of performance and 4096-bit memory bus, and offers the performance of up to 100 CPUs in a single GPU
- NVIDIA Tesla P100 powered by NVIDIA Pascal architecture is designed for accelerating both HPC and AI. It is a low-end data center GPU as it provides only up to 21 teraflops of performance, 16GB of memory, and a 4096-bit memory bus.
- NVIDIA Tesla K80 is designed to accelerate data analytics. It is powered by NVIDIA Kepler architecture and provides 4992 NVIDIA CUDA and GPU Boost technology, 24 GB of GDDR5 memory, and 480 GB/s aggregate memory bandwidth.
- Standard version of Google tensor processing unit (TPU) provides up to 420 teraflops of performance and 128 GB high bandwidth (HBM) memory each. Still, there is a version that provides over 100 petaflops of performance, 32TB HBM.
DGX for deep learning at scale
NVIDIA DGX systems are full-stack AI solutions. In general, they are AI data centers-in-a-box. They are designed specifically for machine and deep learning tasks and show enterprise-grade performance. Moreover, they are really convenient to use due to the plug-n-play philosophy.
For enterprises, many cnvrg.io customers benefit from the DGX workstations, as cnvrg.io provides the easiest way to manage your DGX workstation for deep learning projects. DGX provides teams with a variety of servers for teams that need to run diverse workloads in parallel. You can learn more about our DGX integration here.
As of today, you might need to take a closer look at:
- DGX-1 was the first system in the DGX concept. It has 8 NVIDIA Tesla v100 Tensor Core GPUs with 16GB of memory aboard and provides 1 petaflops of performance. However, since the DGX-2 system was presented DGX-1 is not relevant anymore.
- DGX-2 is an upgrade over DGX-1. Just as its ancestor DGX-2 is an AI server for the most complex deep learning challenges. Powered by NVIDIA DGX software and the scalable architecture of NVIDIA NVSwitch each DGX-2 has 16 NVIDIA Tesla v100 Tensor Core GPUs with 32 GB of memory integrated and provides 2 petaflops of performance.
- DGX A100 is designed to be a universal system for any AI workload, for example, training, testing, inference and analytics. DGX A100 is the first AI system built on NVIDIA Tesla A100 Tensor Core GPU. Each DGX A100 system has 8 A100 GPUs with 40 GB memory and provides 5 petaflops of performance.
What is the best GPU for deep learning?
Generally, the best GPU for deep learning is the one that fits your budget and the deep learning problems you want to solve. At the moment, the best NVIDIA solutions you can find are:
- RTX 30 series – all video card from this series will be a great fit for your deep learning infrastructure
- NVIDIA TITAN V – if you want a consumer-grade GPU that provides datacenter-grade performance on some tasks
- NVIDIA Tesla A100 – as it seems like the best datacenter-grade GPU right now
- Google tensor processing unit (TPU) – for raw power and Google Cloud service convenience
- DGX A100 and DGX-2 – as full-stack AI solution with limitless potential to power your business
My personal choice is the latest consumer-grade GPU from the NVIDIA GEFORCE series. First, it effectively covers all the deep learning tasks you can even think of without any issues. Second, it is quite cheap compared to the datacenter-grade GPUs.
Metrics to monitor GPU performance
Now it is time to think of assessing the GPU performance as we want it to run at full power. To tell the truth, many deep learning projects utilize only a small part of their GPU potential because of different mistakes. Also, a GPU is simply a hardware device that can break or underperform for various reasons. That is why you need to know what to look out for in order to identify the possible problem.
To start with, if you are using an NVIDIA GPU device, you must try NVIDIA’s system management interface. The interface comes with the GPU, so you can easily use a Terminal command to access it.
nvidia-smi -l
The interface constantly monitors your system and displays the percent rate of your GPU utilization. Thus, you will be able to assess it and identify bottlenecks in your deep learning pipelines. For example, if your batch forming takes a lot of time, your GPU utilization will fluctuate from 100% to 20% or less. This approach will help you to optimize your pipelines. You might even decide to add another GPU to your system if your initial one is always utilized at maximum.
The interface is also really effective when talking about memory usage. It has a comprehensive list of memory metrics, so you will have no problem assessing your GPU memory access and usage. It is crucial as this metric will help you to identify the percentage of time your GPU’s controller is actually in use. Thus, you will be able to evaluate the efficiency of your deep learning pipeline and make some adjustments, for example, change the batch size.
Also, it is a good practice to monitor the power consumption and the temperature of your GPU. The power metric will help you to predict and control the power consumption whereas the temperature metric will indicate if your cooling system works fine or you need to make some adjustments in order to prevent the potential hardware damage. Please pay attention to these metrics as they can save your hardware.
To sum up, in order to assess your GPU’s performance you must look out for GPU utilization, GPU memory access and usage, power consumption, and temperature. Keep track of these metrics and your GPU will be used at its maximum. Please use NVIDIA’s system management interface as it is a great tool to monitor your GPU’s performance
Actions you can take to improve GPU utilization
As mentioned above, you can make adjustments to deep learning pipelines to improve your GPU utilization. Here is what you can do:
- Increase the batch size
- Use asynchronous mini-batch allocation
- If you are preprocessing images on the fly, try to preprocess all the files, save them in a more efficient structure, for example, pickle, and construct batches from the raw numpy arrays
- Use multiprocessing to improve batch generation speed
How to use GPU for deep learning?
As mentioned above, you can massively accelerate a neural network training process simply by running it on a GPU. In previous sections, you have learned the reasons behind that. Now let’s move on and discuss how to actually work with GPUs.
To tell the truth, the answer is really simple but it depends on the deep learning framework you are using. As you might know, there are many DL frameworks out there, for example, TensorFlow (TF), Keras, PyTorch, MxNet, and others. Each one of them supports training on a GPU. However, for some of them, it will be easier.
What is CUDA?

To start with, let’s talk a bit about Compute Unified Device Architecture or CUDA. CUDA is a parallel computing platform and programming model developed by NVIDIA that focuses on general computing on GPUs. CUDA speeds up various computations helping developers unlock the GPUs’ full potential.
CUDA has its drivers that can be used to communicate with a GPU. Thus, all deep learning frameworks in one way or another use CUDA to properly run on a GPU. This makes CUDA a really useful tool for data scientists. In order to have the latest version of CUDA installed please update your NVIDIA driver.
Overall, CUDA is a very popular tool due to its high-level structure, so if you have a GPU from NVIDIA you must definitely try it out. Still, CUDA does not work with non-NVIDIA GPUs which makes sense given CUDA’s developer.
What is cuDNN?

The NVIDIA CUDA Deep Neural Network library or cuDNN is a GPU accelerated library that helps to achieve NVIDIA GPUs’ full potential. It has a set of basic functions implemented, for example, various convolutions, activation and pooling layers, and many more.
You should not worry about installing cuDNN as it is already included in all popular deep learning frameworks. You should simply update your NVIDIA driver in order to use the latest version of cuDNN.
Let’s make this clear. cuDNN is the library that is optimized for working on GPUs and has highly tuned implementations for standard deep learning routines. On the other hand, CUDA is the tool that connects deep learning frameworks with cuDNN, communicates with a GPU, and ensures the code will be properly executed on it.
How to train on GPU with PyTorch?
PyTorch seems like the easiest DL framework to train on a GPU as it natively supports CUDA. CUDA can be accessed in the torch.cuda library. The concept of training your deep learning model on a GPU is quite simple. You should just allocate it to the GPU you want to train on.
net = MobileNetV3() #net is a variable containing our model
net = net.cuda() #we allocate our model to GPU
From this point, your model will store on the GPU and the training process will be executed there as well. It is worth mentioning that all the data you want to train on must be allocated to the same GPU as well or you will face errors. Anyway, you can easily do that by using a .cuda() method.
Fortunately, PyTorch does not require anything complicated to carry out this task, unlike some other frameworks. From my perspective, PyTorch is the best deep learning framework option that makes your coding process intuitive and smooth. However, you might feel the other way. For extra support, you can access the in-depth article from cnvrg.io on this topic for further code and documentation.
How to train on GPU with TensorFlow?
You should not expect any obstacles if you want to train your deep learning model on a GPU using TensorFlow. There were times when Tensorflow actually had two packages, the GPU and the CPU one. You can still install them via pip using TF release 1.15 or older:
pip install tensorflow==1.15 # CPU
pip install tensorflow-gpu==1.15 # GPU
Nowadays, since TensorFlow 2.0 these are not separated and you simply need to install TF. It will already include GPU support if you have an NVIDIA card or CUDA already installed:
pip install tensorflow
TensorFlow code, and tf.keras models will automatically run on a single GPU with no code changes required. You just need to make sure TensorFlow detects your GPU. You can do this using a simple command.
import tensorflow as tf
print(“Num GPUs Available: “, len(tf.config.experimental.list_physical_devices(‘GPU’)))
If the number printed is more than zero, it means TensorFlow has successfully detected your GPU. That is all it takes for your future TensorFlow code to run on the GPU by default. Still, you will be able to perform computation on a CPU without any difficulties. To tell the truth, there is a great notebook from the developers’ team that covers TensorFlow GPU support in-depth. Please access it for extra support.
How to train on GPU with Keras?
Nowadays, Keras is completely integrated with TensorFlow. The original Keras library is not maintained or updated anymore. That is why when talking about Keras data scientists usually refer to the Keras API integrated into TensorFlow.
Let’s make this clear. Keras is a high-level API that deeply integrates with low-level TF functionality. It means you can use Keras methods without having to figure out how it interacts with TensorFlow.
Thus, everything mentioned above about TensorFlow GPU support is true with Keras.
How to train on GPU with MxNet?
To tell the truth, there is not much to say about MxNet. The concept it uses to run deep learning models on GPUs is similar to the PyTorch concept. You simply need to specify a hardware device you want to train on, allocate your model and data to the same GPU and start training. For more information please refer to the official MxNet tutorial.
Using distributed training to accelerate your workload
Training a neural network is a complicated and time-consuming process. Even if you do this on a GPU, it might take ages for your model to fully train. Sure the time needed for that depends on the task and the network complexity, however, you might want to use some advanced techniques to speed up the training process even more.
For example, you can use the distributed training technique. In this case, the name speaks for itself. Distributed training suggests dividing your training process on different workloads across so-called worker nodes. Nodes are actually GPU’s mini-processors that are used to parallelize tasks. If you remember the GPUs thread parallelism feature we discussed earlier, you must have already guessed it is achieved by worker nodes. So, when talking about distributed training we refer to the training process parallelization concept.
In general, there are two completely different types of distributed training:
- Data parallelism
- Model parallelism
Data parallelism
The first type is known as data parallelism. The concept is quite simple:
- You make a copy of your initial model for each worker node
- You train each copy on a different batch of training data. Thus, your data will be split up and processed in parallel
- You combine the results after computations and update your initial model
- You repeat steps 1 – 3 until your network is trained

In general, data parallelism is a very efficient concept. However, it has a major disadvantage. Sometimes the neural network is so large that it can not fit on a single worker node. In this case, the data parallelism concept will not work at all.
Model parallelism
However, that is where the second type of distributed training called model parallelism comes in. The concept suggests dividing a model into several different parts and training them simultaneously across worker nodes. Moreover, all worker nodes use the same dataset and from time to time share global model parameters with other workers. Thus, model parallelism helps to solve the problem of large neural networks.

Unfortunately, the model parallelism concept has major disadvantages. First, it will work well only if the initial neural network model has a parallel architecture. Second, this type of distributed training is really hard to implement code-wise. That is why the data parallelism concept is more commonly used.
Multi-GPU
Still, if you have a large neural network, there is a technique besides model parallelism that can be used to improve deep learning performance. It is called multi-GPU processing and can be used only if you have several GPUs aboard.
If it is true to your system, you must definitely try multi-GPU processing as it will be both fast and effective. There are two ways of working with multiple GPUs. The first approach suggests using each GPU for a separate task. Thus, you will be able to experiment and run multiple algorithms at once. However, you will not achieve better speed.
The second type requires combining several GPUs in one computer (making a GPU cluster) to achieve better performance. It is called GPU parallelism and can be used to work with the data parallelism concept with no fear of the large neural network obstacle. Let’s make this clear. You can simply use each separate GPU as a worker node. Thus, your model’s performance will improve drastically.
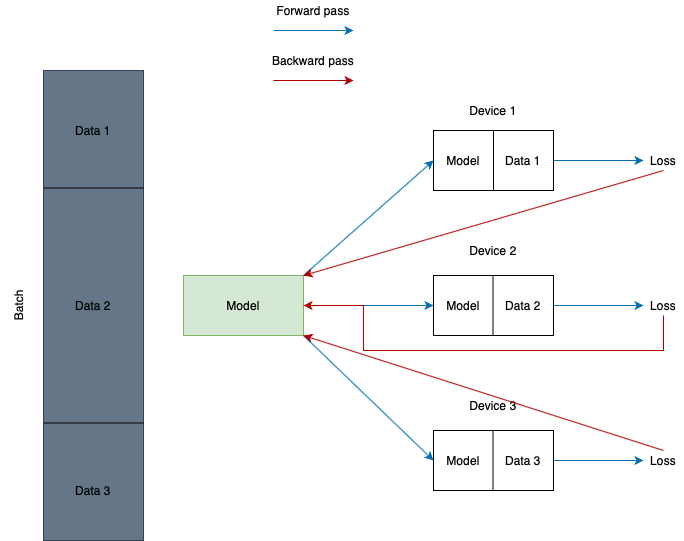
As far as I am aware all modern deep learning frameworks (PyTorch, TensorFlow, Keras, and MxNet) are up to the task. Moreover, there are deep learning frameworks, for example, Horovod that specialize in distributed learning. Feel free to explore the opportunities as the industry is constantly evolving. From the coding perspective, you should not face any obstacles. Please refer to the tutorials linked above for extra-support.
Synchronization methods
Unfortunately, distributed training has its own challenges, for example, determining how different worker nodes will share and synchronize their results. There are two approaches to this problem: a parameter server technique and an all-reduce technique.
A parameter server-based architecture suggests dividing all GPU nodes into two groups. The first group consists of nodes called workers which train a neural network model. The second one consists of nodes called parameter servers which preserve the global parameters of a model. Thus, the workers will receive the global parameters from a parameter server, calculate gradients with their data batches and return the results to a parameter server.
Still, a parameter server-based architecture has major disadvantages. To start with, if the global model parameters are synchronously shared across workers, you will wait until each worker completes its iteration and returns the results which might be time-consuming. Also, if you have only one parameter server, you will not benefit from adding more workers as your server will have to work with more data from the workers which creates a bottleneck.
The all-reduce approach limits the disadvantages of a parameter server-based technique as it suggests each node to store a neural network global parameters. To tell the truth, there are various all-reduce algorithms, but overall it is a powerful technique as it allows to add more workers without any limitations. Thus, it is used more often than a parameter server-based architecture.
Deep Learning on GPU clusters
A GPU cluster concept is based on having multiple GPUs aboard. In general, a GPU cluster is a computing cluster in which each node is equipped with a Graphics Processing Unit. Moreover, there are TPU clusters that are more powerful than GPU clusters.
Still, there is nothing special in using a GPU cluster for a deep learning task. Imagine you have a multi-GPU deep learning infrastructure. You could either use each GPU for a specific task or try a distributed training data parallelism technique to utilize your GPUs effectively. Moreover, you could follow your own logic and play with your system as you wish. Despite a GPU cluster being way more powerful the same is true to using it.
What is Mixed Precision?
Let’s continue with advanced techniques and talk about Mixed precision. It is an interesting technique that requires using both 16-bit and 32-bit floating-point types in a neural network model during training to make it run faster and use less memory. The concept suggests keeping certain parts of the model in the 32-bit types for numeric stability. Thus, the model will have a lower step time while training equally as well in terms of the evaluation metrics. For extra support and code please refer to the official notebook concerning this technique.
Overall, mixed precision is an advanced technique that can be used effectively if you study it. So, feel free to experiment and play with it.
What is NVIDIA SDK?
Last but not least, let’s cover the NVIDIA Software development kit (SDK). NVIDIA CUDA-X AI is an SDK designed for effective deep learning model building which can be easily used with an NVIDIA GPU. It includes multiple GPU-accelerated libraries for AI and high-performance computing (HPC). There are libraries for:
- Deep learning routines
- Linear algebra
- Matrix operations
- Multi-GPU communication
- And many more
Overall, NVIDIA CUDA-X AI is designed for computer vision (CV) tasks and recommendation systems. The SDK can be used to accelerate your deep learning framework and build new model architectures directly for a GPU. CUDA-X AI libraries offer a unified programming model that enables you to develop deep learning models on your desktop. However, you should not overcomplicate things. NVIDIA SDK is an advanced tool, so you might probably want to return to it when you have mastered the basics of training on a GPU.
Cloud services vs. On-premise approach
Let’s talk a bit about cloud technologies. In general, when choosing your deep learning infrastructure you must choose whether you will use an on-premise or a cloud approach.
An on-premise approach requires having a computer with at least one hardware device that can be used to train a neural network model effectively. From my experience, it might be enough for personal usage especially if you have a high-end consumer-grade GPU aboard. You will be able to work on any deep learning task but the time needed for your models to train can be significant (although it depends on your system configuration). Moreover, building an on-premise infrastructure might be very expensive. Still, such an approach is really flexible as all the hardware you have will be yours. You will be able to perform as many experiments as you want and train your models as long as you want. Also, using an on-premise approach you can control hardware configurations and security. Thus, an on-premise infrastructure allows you to explore the task from all the angles you want with stable costs and enormous flexibility.
On the other hand, there is a cloud approach that requires less money to start using. Also, the majority of cloud services provide scalability and provider support. Moreover, you will be able to get access to more powerful hardware, for example, TPU clusters. Unfortunately, cloud services are not as flexible and if you use them consistently it might cost you a lot.
Moreover, when companies move workloads and data to the cloud, their on-premise infrastructure often continues to play an important role. A combination of on-premise infrastructure and cloud service is known as hybrid cloud. Some organizations use hybrid cloud as a path to migrate their entire datacenter to the cloud over time. Other organizations use cloud services to extend their existing on-premises infrastructure.
A hybrid solution might be useful in multiple situations. For example, it might serve as a transition step during a longer-term migration to a fully cloud-native solution or for disaster recovery and fault tolerance by replicating data and services between on-premises and cloud environments. Moreover, it might help to reduce latency between your on-premise infrastructure and remote locations by hosting part of your architecture in a cloud.
Enterprises are transitioning to hybrid cloud, and for a good reason. Cloud services can be great for short-term projects and for organizations that are just getting started. However, for long-term and large projects or personal everyday usage, an on-premise approach is the one to choose as it will spare you loads of money. Still, a hybrid solution might be really useful in some scenarios as well.
Best practices, tips and strategies
Throughout this article I mentioned plenty of valuable tips you might want to remember after reading this article, so let’s summarize them into a list:
- A GPU is a part of a video card. However, these terms often interchange with one another
- When solving a deep learning problem GPU is more powerful than CPU
- A CPU is good in the tasks where latency or per-core performance is important
- GPUs often perform better than CPUs for deep learning projects
- Still, both ASICs and FPGAs are a more powerful hardware tool than GPUs as they are specialized and tuned to solve a particular task
- It is easier to use a GPU for your deep learning project
- A GPU will make your training process fast
- You can make it even faster using parallelization
- You will be able to process large datasets using a GPU
- When choosing a GPU you must look out for the memory bandwidth, the number of cores, video RAM size, and processing power
- As of today, NVIDIA GPUs are the best ones for deep learning tasks
- When assessing your GPU’s performance you must pay attention to the GPU utilization, GPU memory access and usage, power consumption, and temperature
- CUDA is a tool that is used to communicate with a GPU
- cuDNN is the library that is optimized for working on GPUs and has highly tuned implementations for standard deep learning routines
- It is easy to train your model on a GPU using any modern deep learning framework
- You can use distributed training to enhance your deep learning performance even more
- Model parallelism is not a commonly used technique
- Multi-GPU processing works perfectly with the data parallelization concept as it limits the drawbacks of the large neural networks
- Mixed precision is an interesting technique that is not commonly used
- NVIDIA SDK is an advanced tool that can be properly used only if you mastered the basics
- You might want to try cloud services for short-term projects
- On-premise infrastructure offers flexibility, security and stable costs
- If you are building a deep learning infrastructure, you must select the right resources. Please consider the complexity of the deep learning tasks you need to solve and make your choice among GPUs or cloud services based on that knowledge. If you have chosen an on-premise approach, you should study the GPU market using the criteria mentioned above to find the best GPU for your task within your budget
- NVIDIA provides a great set of the model’s architecture examples for various deep learning tasks (Computer Vision, NLP, Recommender Systems, and more)
- You should explore your opportunities as you might find something interesting. For example, cnvrg.io and NVIDIA DGX Data Science Solution. The cnvrg.io platform, running on NVIDIA DGX Systems, provides data scientists with accelerated data science project execution from research to production. All tools for building, managing, experimenting, tracking, versioning, and deploying models are available with one-click
Final Thoughts
Hopefully, this article will help you succeed and use your GPU in your next Deep Learning project effectively.
To summarize, we started with an in-depth comparison of different hardware devices such as GPU, CPU, ASIC, and FPGA, and went through a step-by-step guide on how to choose and assess a GPU. Also, we talked about training neural networks on a GPU from the code perspective. Lastly, we considered some advanced techniques and tools that can be used to accelerate the training process.
If you enjoyed this post, a great next step would be to start building your own Deep Learning project with all the relevant tools. Check out tools like:
- An NVIDIA GPU as a hardware device,
- cnvrg.io as an MLOps tool
Thanks for reading, and happy training!
Resources
- https://www.intel.com/content/www/us/en/products/docs/processors/cpu-vs-gpu.html
- https://www.intel.com/content/www/us/en/artificial-intelligence/programmable/fpga-gpu.html
- https://missinglink.ai/guides/computer-vision/complete-guide-deep-learning-gpus/
- https://docs.nvidia.com/sdk-manager/introduction/index.html
- https://cloud.google.com/tpu
- https://cnvrg.io
- https://www.nvidia.com/en-us/
- https://www.amd.com/en
- http://www.juyang.co/distributed-model-training-ii-parameter-server-and-allreduce/







