CI/CD (Continuous Integration/Continuous Deployment) has long been a successful process for most software applications. The same can be done with Machine Learning applications, offering automated and continuous training and continuous deployment of machine learning models. Using CI/CD for machine learning applications creates a truly end-to-end pipeline that closes the feedback loop at every step of the way, and maintains high performing ML models. It can also bridge science and engineering tasks, causing less friction from data, to modeling, to production and back again.
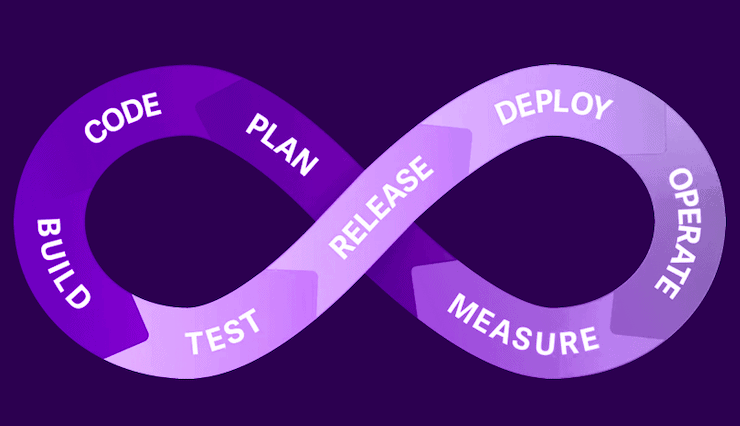
CI/CD for Software Development Applications
CI/CD is a practice derived from DevOps, allowing you to deliver code and deploy it quickly, whether it be your customer or application, to production. This results in an automated pipeline enabling you to write code and have it production-ready, fast. CI/CD in software development has multiple stages: First, you start with a product request, a plan, you code it, build, and then run many tests. Once the testing phase is completed it will transition from CI continuous integration), to CD (continuous deployment). It begins with defining the release, followed by deployment, operations, and monitoring of the application in production.
CI/CD is an ongoing process of updating, reassessing, recognizing issues in the model and going back to alter the model according to the new data, then back again. It automates your machine learning pipeline (building, testing and deploying) and greatly reduces the need for data scientists to intervene in the process, making it more accessible to wider audiences and less prone to human error, as the feedback loop guarantees a constant improvement of the models’ accuracy and performance.
Enhance machine learning accuracy with CI/CD
The benefit of applying CI/CD practices when building a machine learning pipeline mostly has to do with its scalability. When working on smaller scales, perhaps only on a few models, you can manage without using practices like CI/CD. However, nowadays most organizations implementing machine learning pipelines require greater complexity and scale. Building models at the enterprise level requires running hundreds of experiments simultaneously, which becomes increasingly difficult to manage without a robust framework. This robust framework often causes hidden technical debt, and mismanaged DevOps challenges. This is where CI/CD practices come in handy, with a framework to allow continuous improvement so that your machine learning models are always performing in production, with improved model performance and accuracy, so that you can see a gradual improvement over time.
CI/CD practices in a machine learning pipeline automate the process of model training, model research and model deployment, streamlining the workflow and making it feasible to run ML pipelines at greater scales.

Machine learning pipelines include data collection, data verification, resource management and DevOps assistance consisting of large scale compute resources. With varying types of infrastructure, whether cloud or on-premise, you need to make sure that your models will yield production-ready, accurate results that will improve over time. However your models are never permanent structures, they are ever-changing according to the new data, as model decay gives rise to the need to retrain your models. CI/CD can be used to create a constant feedback loop, assuring that your models are updated and accurate without needing your constant attention, supervision, and intervention.
Continual Machine Learning Pipeline
A machine learning pipeline begins, of course, with data. Data validation and various data checks are required in order to verify that your data is suitable. Then there’s model training, using different algorithms, to find the right fit for the model. Additional model testing leads up to the deployment of models to production. The deployment and the prediction stages need to be done safely, then you need to confirm a feedback loop in order to get the data from your predictions tested in data validation in order to ascertain whether model retraining is required. Depending on a variety of factors, an automated model may need to be retrained on a daily, hourly or even minute by minute basis. This process of retraining is the part managed via continuous integration, CI, keeping in mind that your data may need to comply with various regulations such as GDPR or other required constraints. Statistical tests and anomaly detection will further strengthen your control of the CI/CD pipeline, making sure your data is valid and your models’ predictions accurate. Continual machine learning pipelines have the unique attribute of refining and improving over time. Keep in mind that testing and monitoring the accuracy is crucial for maintaining a robust, production-ready pipeline. Having an end to end platform like cnvrg.io eliminates the need for extensive DevOps and data science friction, applying the tools for a fully automated CI/CD ML pipeline.
Model training phases introduce a great deal of uncertainty into the machine learning pipeline. Testing many different algorithms and hyperparameters, you need to make sure to have a flexible tool in order to anticipate the inevitable changes and adjust your pipeline accordingly.
Model Tracking & Monitoring
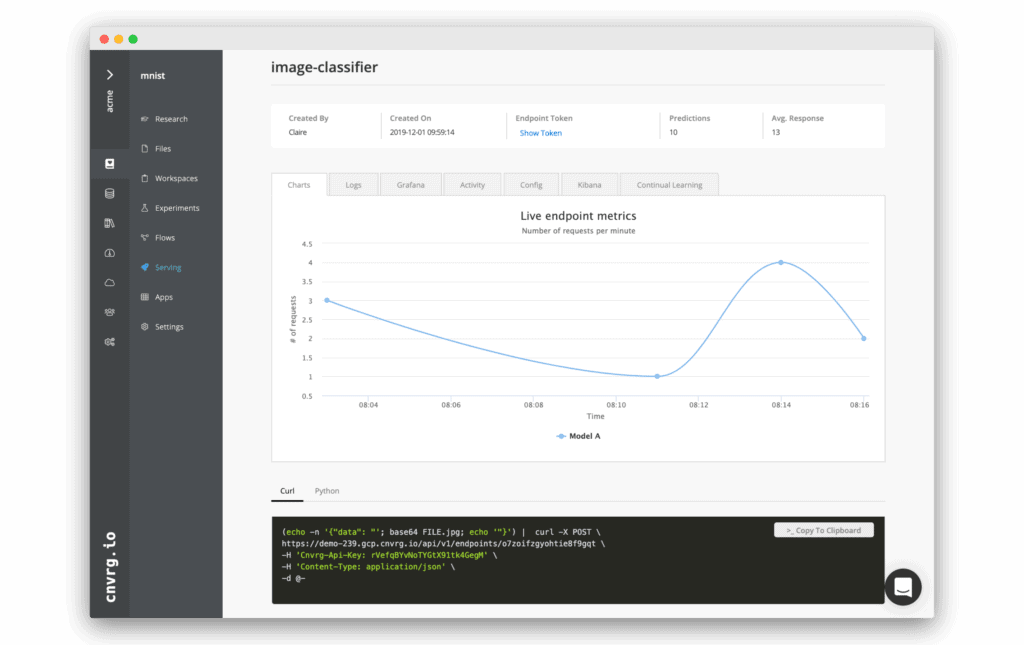
As machine learning pipelines typically include hundreds of models, tracking your experiments becomes a crucial point. The algorithms used, the hyperparameters used, the resources consumed, the system utilized is all material for your production models and results. Having reproducible, tracked data science is of cardinal importance, and allows collaboration and predictability.
Once you deploy your models, it is recommended to use a gradual approach like the Canary release, gradually deploying across your production environment. Deployed models require tracking in production, specifically monitoring for machine learning health. Setting triggers in order to retrain the models upon model decay is recommended, this is the continuous deployment part of the pipeline, assuring you are always production-ready.
Having a business dashboard is very helpful in communicating the results of the data science teams’ models to the business units. Measuring your KPIs, creating alerts and triggers, are essential for maintaining your ML pipeline in a fully functional state.
Continual learning is a method employed by the cnvrg.io platform to instantly apply continuous integration and continuous deployment of your machine learning pipeline. The feature allows you to create alerts that are triggered when your model drops below a certain confidence level threshold. This makes your pipeline extremely robust, and always production-ready. It ensures high performance, high availability models, with a high level of accuracy and health, as the models keep improving over time.
Interested in learning more about CI/CD for machine learning? See our Free Webinar here